
명령어의 구조는 어떻게 되어있는가?
연산 코드와 오퍼랜드
--
일반적으로 명령을 할 때
"대상"과 "동작"을 포함하여 말한다.
[ ex) A와 B를 더해 ]
명령어는 "연산 코드"와 "오퍼랜드"로 구성되어 있다.
- 연산 코드 (Operation code) : 명령어가 수행할 연산(동작)
- 오퍼랜드 (Operand) : 연산에 사용할 데이터 or 연산에 사용할 데이터가 저장된 위치
여기서
연산 코드를 연산자
오퍼랜드를 피연산자라고도 부른다.
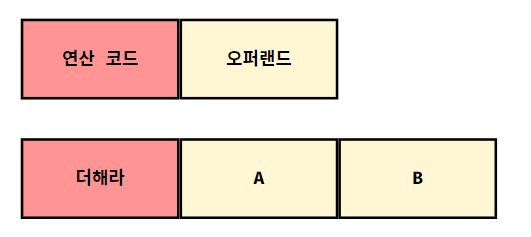
위 그림처럼
오퍼랜드는 하나의 명령어 안에 하나도 없을 수도 있고, 1개만 존재할 수 도 있으며, 여러 개가 존재할 수도 있다.
이때
오퍼랜드가 0개인 명령어 = "0-주소 명령어"
오퍼랜드가 1개인 명령어 = "1-주소 명령어"
오퍼랜드가 2개인 명령어 = "2-주소 명령어"
라고 부른다.
연산 코드가 담긴 영역을 "연산 코드 필드"
오퍼랜드가 담긴 영역을 "오퍼랜드 필드"
라고 부른다.
오퍼랜드
"연산에 사용할 데이터" or "연산에 사용할 데이터가 저장된 위치"를 의미한다.
그래서 오퍼랜드 필드에는
숫자, 문자 등을 나타내는 데이터나 레지스터 주소가 올 수 있다.
다만 일반적으로 직접 연산의 데이터(숫자, 문자 등)를 명시하기보단
해당 데이터의 메모리 주소나 레지스터 이름을 담는다.
그래서 "오퍼랜드 필드"를 "주소 필드"라고도 부른다.
연산 코드
"명령어가 수행할 연산(동작)"을 의미한다.
연산 코드의 종류는 매우 다양하지만, 가장 기본적인 연산 코드 유형
- 데이터 전송 ( 데이터 이동, 저장 등 )
- 산술/논리 연산 ( 사칙연산, AND, OR, False, True 등 )
- 제어 흐름 변경 ( 실행 순서, 실행 중지 등 )
- 입출력 제어 ( 데이터 읽기, 쓰기, 입력 등 )
--
주소 지정 방식
--
오퍼랜드 필드에 메모리(주소)나 레지스터의 주소를 담는 경우가 많으며
이러한 경우 "오퍼랜드 필드"를 "주소 필드"라고 부르기도 한다.
이때 연산에 사용할 데이터의 위치를 찾는 방법을 "주소 지정 방식(Addressing Model)"이라고 한다.
오퍼랜드에 직접 데이터를 담지 않고 주소를 담는 이유
바로 해당 명령어의 길이 때문이다.
하나의 명령어가 n비트로 구성되어야 한다고 치면
n비트 중에서 연산 코드 필드가 m비트를 차지한다.
그러면 오퍼랜드 필드에 할당할 수 있는 공간은 n-m비트가 된다.
하나의 명령어에 오퍼랜드의 개수가 많아질수록 각 오퍼랜드 필드의 크기는 줄어들게 된다.
그래서 오퍼랜드 필드에 직접 데이터를 담는 것보다 해당 데이터의 주소를 담는 것이 차이하는 데이터의 크기가 작기 때문에 직접 데이터를 담는 방법보다 주소를 담는 방법을 사용하게 된 것이다.
주소 지정 방식의 대표적인 5가지 방식
- 즉시 주소 지정 (Immediate Addressing)
- 직접 주소 지정 (Direct Addressing)
- 간접 주소 지정 (Indirect Addressing)
- 레지스터 주소 지정 (Register Addressing)
- 레지스터 간접 주소 지정 (Register Indrect Addressing)
즉시 주소 지정 방식
오퍼랜드 필드에 직접 데이터를 명시하는 방식이다.
- 데이터를 메모리나 레지스터에서 찾는 과정이 없으므로 상대적으로 빠르다.
- 데이터의 크기가 작아진다. (오퍼랜드 필드의 공간은 한정적이므로 큰 데이터 사용이 불가능)

직접 주소 지정 방식
오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식이다.
즉, 사용할 데이터가 저장되어 있는 실제 메모리 주소를 명시하는 방식이다.
- 사용할 데이터의 주소를 바로 담았기에 쉽게 해당 데이터에 접근이 가능하다. (즉시 주소 지정 방식보다는 느림)
- 직접 데이터를 담지 않고 주소를 담았기에 데이터의 크기와 상관없이 오퍼랜드 필드에 공간을 차지한다.
- 오퍼랜드 필드의 공간이 한정적이므로 표현할 수 있는 주소의 범위가 제한된다.
(16비트 오퍼랜드 필드는 2^16개의 주소만 지정 가능) - 메모리 주소는 고정적으로 실행 중 동적으로 변경이 어렵다.
(3858494 데이터를 직접 사용 중이므로 다른 데이터의 유효 주소로 변경이 어렵다.)
(즉, 실행 중에는 오퍼랜드에 명시한 유효 주소 변경이 불가능하여 다른 메모리 공간에 있는 데이터로 변경이 어려움)

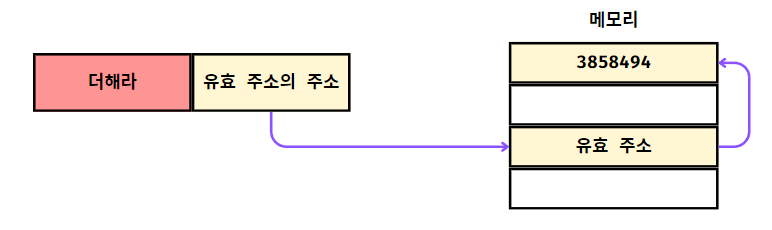
간접 주소 지정 방식
직접 주소 지정 방식과 비슷하지만
오퍼랜드 필드에 유효 주소의 주소를 명시하는 방식이다.
즉, 사용할 데이터를 두 번 걸쳐서 접근할 수 있는 방식이다.
- 메모리 주소가 실행 중 동적으로 변경이 가능하다.
(실행 중에 유효 주소의 주소 변경은 불가능하지만 유효 주소는 다른 데이터를 가리키도록 변경이 가능하기 때문) - 유효 주소는 얼마든지 자유롭게 다른 데이터의 주소를 가리킬 수 있으니 더 큰 주소 범위를 참조할 수 있다.
(주소의 범위 제한이 더 넓어진다.)
- 간접적으로 접근하기 때문에, 최소 두 번의 메모리 접근이 필요하여 속도가 상대적으로 느려진다.
- 디버깅이 복잡해질 수 있다.
레지스터 주소 지정 방식
직접 주소 지정 방식과 비슷하지만
데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시하는 방식이다.
- 데이터에 접근하는 속도가 빠르다.
(CPU 외부에 있는 메모리에 접근보다 CPU 내부에 있는 레지스터에 접근이 더 빠르다.) - 메모리 대신 레지스터를 사용함으로 CPU의 처리 효율이 증가한다.
- 직접 주소 지정 방식처럼 레지스터 크기(수)에 제한이 생길 수 있다.
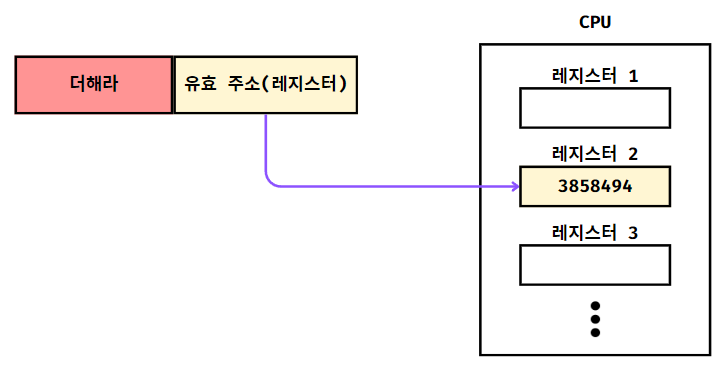
레지스터 간접 주소 지정 방식
간접 주소 지정 방식과 비슷하지만
연산에 사용할 데이터는 메모리에 저장하고,
해당 메모리 주소(유효 주소)를 레지스터에 저장 후 오퍼랜드 필드에 레지스터를 명시하는 방식이다.
- 간접 주소 지정 방식과 비슷하지만 메모리에 접근하는 횟수가 한 번 줄어든다. (메모리가 아닌 레지스터를 사용해서)
- 간접 주소 지정 방식보다 빠르다.
- 레지스터의 값을 통해 다양한 메모리 위치를 쉽게 참조 가능하다.
- 사용 가능한 레지스터의 수는 한정적이므로 많은 데이터 처리에 제약이 있다.
- 간접적인 메모리 접근으로 인해, 코드가 더 복잡해질 수 있다.

--
'CS > 컴퓨터 구조' 카테고리의 다른 글
| [CPU 동작 원리] 레지스터 종류 (0) | 2024.08.24 |
|---|---|
| [CPU 작동 원리] ALU와 제어장치 (0) | 2024.08.23 |
| [명령어] 고급 언어와 저급 언어 ( 컴파일, 인터프리터 ) (0) | 2024.08.21 |
| 데이터 (0과 1로 문자, 숫자를 표현하기) (0) | 2024.08.20 |
| 컴퓨터 구조 (+전체적인 구조 간단 설명) (2) | 2024.08.19 |