프로그램은 실행되기 전까지는 그저 보조기억장치에 저장되어 있는 데이터일 뿐이지만, 해당 프로그램을 보조기억장치에서 메모리에 적재하고 실행하는 순간 해당 프로그램은 프로세스가 된다. (실행 중인 프로그램)
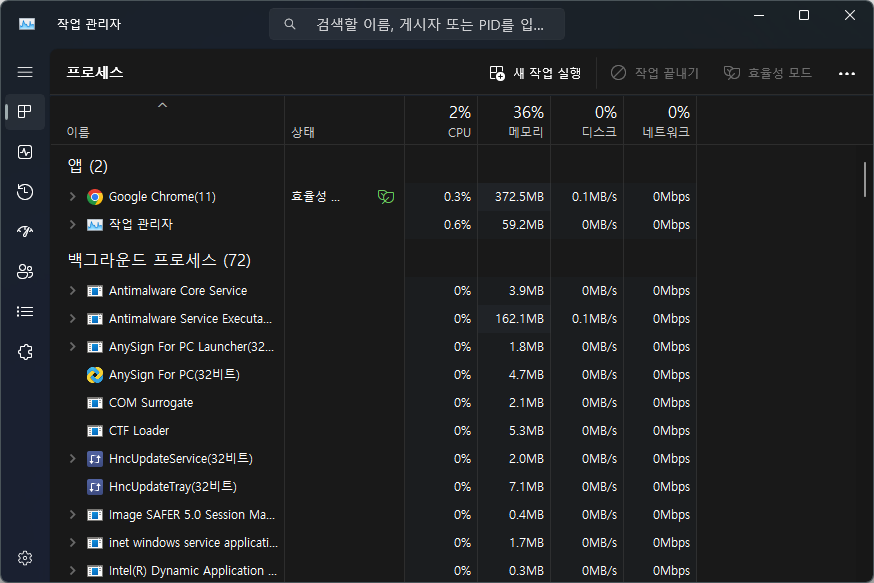
윈도우는 [작업 관리자]를 통해 확인할 수 있다.
포그라운드 프로세스 (foreground process)는
현재 크롬 브라우저, 작업 관리자처럼 사용자가 보는 앞에서 실행 중인 프로세스를 의미한다.
백그라운드 프로세스 (background process)는
사용자가 보지 못하는 뒤(내부)에서 실행 중인 프로세스를 의미한다.
그리고 백그라운드 프로세스 중에서 사용자와 상호작용하지 않고
그저 묵묵히 정해진 일만 수행하는 백그라운드 프로세스를 "데몬(daemon)" 또는 "서비스(service)"라고 부른다.
데몬 (daemon) : 유닉스 계열 운영체제에서 사용하는 용어
서비스 (service) : 윈도우 운영체제에서 사용하는 용어
--
프로세스 제어 블록 (PCB, Process Control Block)
--
PCB는
운영 체제에서 각 프로세스의 상태와 정보를 관리하는 데 사용되는 자료 구조다.
이는 프로그램이 실행되어 프로세스로 변환될 때 운영 체제가 자동으로 생성한다.
(메모리 중에서 "커널 영역"에 생성된다.)
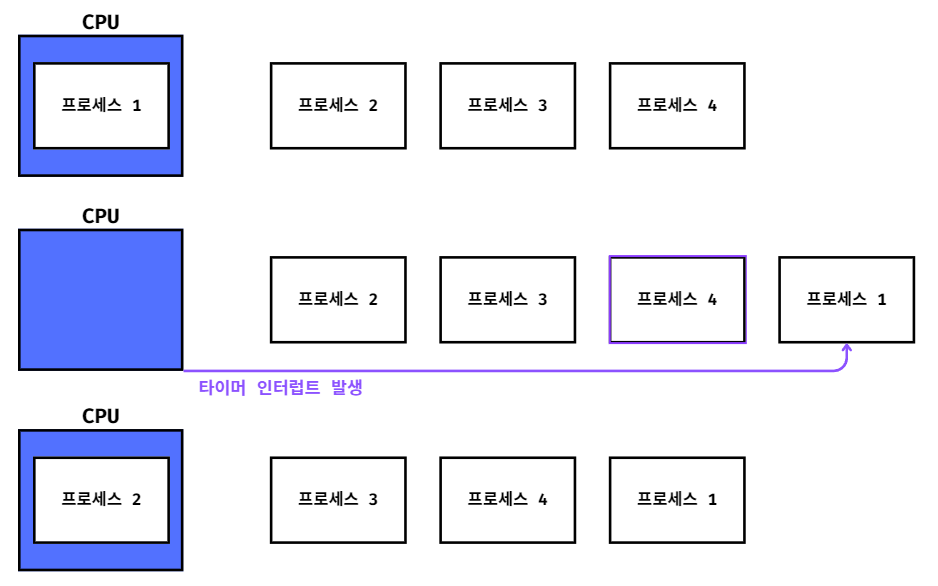
모든 프로세스는 실행을 위해 CPU 자원이 필요하지만
CPU 자원은 한정적이므로 현재 실행 중인 모든 프로세스가 동시에 CPU 자원을 사용하기에는 어렵다.
그래서 PCB를 이용하여
프로세스들을 차례대로 돌아가면서 정해진 시간만큼 CPU 자원을 사용하도록 관리한다.
PCB를 비유해서 설명하자면
옷에 붙여져 있는 태그와 비슷하다고 볼 수 있다.
태그에는 이름, 재료, 가격 등 옷을 식별하기 위한 정보가 담겨 있는 것처럼
PCB도 프로세스를 식별하기 위한 정보들이 담겨 있다.
PCB에 담긴 대표적인 정보 종류
프로세스 식별자 (PID, Process ID) : 각 프로세스를 식별하기 위한 고유 번호
운영체제는 해당 PID 식별자를 통해 프로세스를 구분하고 추적한다.
프로세스 상태 (Process State) : 현재 프로세스에 대한 상태 (준비, 실행, 대기, 종료 등)
현재 프로세스가 CPU 자원을 사용하기 위해 대기 중인지, I/O 장치를 사용하기 위해 대기 중인지, CPU 자원을 사용 중인지 등의 상태 정보를 의미한다.
레지스터 정보 (Registers) : CPU 레지스터에 저장된 값 (프로그램 카운터, 스택 포인터, 일반 레지스터 등 포함)
프로세스가 CPU 자원을 사용할 때의 레지스터 정보들을 저장하여 다음 실행 차례가 돌아오면 해당 레지스터 정보를 보고 이전까지 진행했던 작업들을 이어서 실행하도록 한다.
프로세스 우선순위 (Priority) : 프로세스의 우선순위에 대한 정보
운영체제는 해당 우선순위에 따라 프로세스를 스케줄링하고 CPU를 배정한다.
메모리 관리 정보 (Memory Management Information) : 프로세스가 사용하는 메모리 영역과 관련된 정보
프로세스마다 메모리에 저장된 위치가 다르다. 그래서 어느 주소에 저장되어 있는지 알아야 한다.
입출력 상태 정보 (I/O Status Information) : 프로세스가 사용 중인 입출력 장치 및 파일과 관련된 정보
프로세스가 실행 과정에서 특저 입출력장치나 파일을 사용하면 PCB에 해당 내용이 명시된다. (어떤 입출력장치가 할당되었는지, 어떤 파일을 열었는지 등)
--
문맥 교환
--
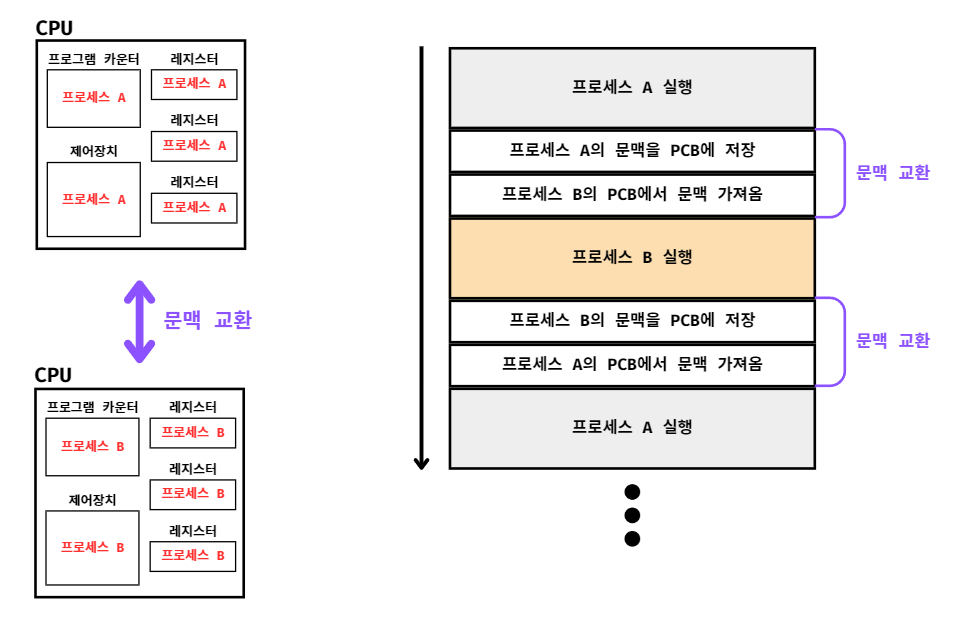
문맥 교환은
여러 프로세스가 끊임없이 빠르게 번갈아 가며 실행되는 원리를 의미한다.
A프로세스에서 B프로세스로 실행 순서가 넘어갈 때
A프로세스의 프로그램 카운터를 비롯한 각종 레지스터 값, 메모리 정보 등 모든 정보를 백업해야
나중에 다시 A프로세스 차례가 왔을 때 이어서 다시 실행할 수 있다.
이렇게 하나의 프로세스 실행을 재개하기 위해 필요한 정보를 "문맥(context)"라고 부른다.
(해당 프로세스의 PCB에 기록되는 정보들을 "문맥"이라고 봐도 무방하다.)
문맥 교환을 자주 하면 그만큼 빨리 번갈아 가며 수행하기 때문에 사용자는 프로세스들이 동시에 실행되는 것처럼 보인다. 다만 문맥 교환을 너무 자주 하게 되면 "오버헤드"가 발생할 수 있기 때문에 반드시 좋은 것은 아니다.
오버헤드 (Overhead)는 컴퓨터 시스템에서 작업을 처리하는데 추가로 발생하는 시간, 자원, 비용 등을 의미한다.
--
프로세스의 메모리 영역
--
프로세스가 생성되면 "커널 영역"에 PCB가 생성된다.
그리고 "사용자 영역"에는 크게 "코드 영역", "데이터 영역", "힙 영역", "스택 영역"으로 나누어 저장된다.
코드 영역 (Code Segment)는
텍스트 영역 (Text Segment)라고도 부르며,
실행할 수 있는 코드(기계어로 이루어진 명령어)가 저장되는 공간이다.
즉, 데이터가 아닌 CPU가 실행할 명령어가 담겨 있기 때문에 읽기 전용 공간이다. (쓰기 불가능)
데이터 영역 (Data Segment)는
프로그램이 실행되는 동안 유지해야 하는 데이터가 저장되는 공간이다.
(잠깐 사용하고 말 데이터가 아닌 계속 가지고 있어야 하는 데이터)
대표적으로 "전역 변수"가 있다.
힙 영역 (Heap Segment)는
개발자가 직접 할당할 수 있는 저장 공간이다.
개발 과정에서 "힙 영역"에 메모리 공간을 할당했다면 언젠가는 해당 공간을 반환해줘야 한다.
(메모리 공간을 반환한다는 것은 운영체제에게 '더 이상 해당 메모리 공간을 사용하지 않는다'라고 전달하는 것과 동일)
메모리 공간을 반환하지 않으면 할당한 공간은 메모리 내부에 계속 남아 메모리 낭비를 발생한다. 이를 "메모리 누수 (Memory Leak)"라고 부른다.
스택 영역 (Stack Segment)는
데이터를 일시적으로 저장하는 공간이다.
즉, "데이터 영역"과 달리 잠깐 사용할 데이터들을 저장하는 공간이며,
대표적으로 "매개 변수", "지역 변수"가 있다.
"코드 영역"과 "데이터 영역"은 크기가 변하지 않는다. 프로그램을 구성하는 명령어들이 갑자기 바뀔 일이 없으며, "데이터 영역"에 저장될 내용들은 프로그램이 실행되는 동안에만 유지하기 때문이다.
반대로 "힙 영역"과 "스택 영역"은 실시간으로 크기가 변할 수 있다. 그래서 일반적으로 "힙 영역"은 메모리의 낮은 주소에서 높은 주소로 할당되고, "스택 영역"은 높은 주소에서 낮은 주소로 할당하여 최대한 "힙 영역"과 "스택 영역"의 데이터들이 서로 겹칠 일이 없도록 구성한다.
"코드 영역"과 "데이터 영역"은 "정적 할당 영역"이라고도 부르며, "힙 영역"과 "스택 영역"은 "동적 할당 영역"이라고 부른다.
--
프로세스 상태
--
프로세스는 모두 각자의 상태가 있으며, 이를 운영체제가 PCB에 기록하여 관리한다.
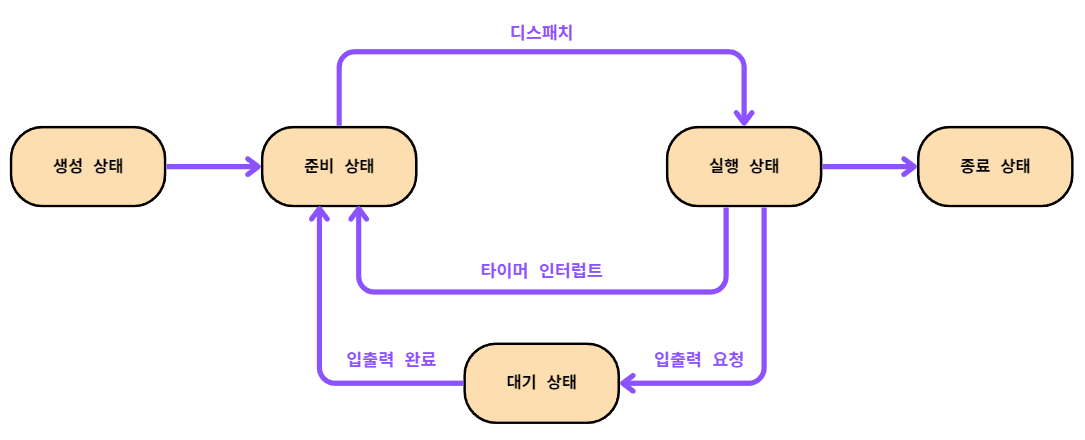
생성 상태 (new)는
프로세스를 생성 중인 상태를 의미하며,
이제 막 메모리에 적재되어 PCB 할당을 받은 상태다.
("생성 상태"를 거쳐 실행할 준비가 완료된 프로세스는 바로 실행되는 것이 아닌 "준비 상태"가 된다.)
준비 상태 (ready)는
해당 프로세스를 당장이라도 CPU를 할당받아 실행할 수 있는 상태를 의미하며,
아직은 자신의 실행 차례가 아니기에 기다리고 있는 상태다.
디스패치 (Dispatch)는 "준비 상태"인 프로세스가 "실행 상태"로 전환되는 것을 의미한다.
실행 상태 (running)는
CPU를 할당받아 실행 중인 상태를 의미한다.
할당된 일정 시간 동안만 CPU를 사용할 수 있으며,
할당된 시간을 모두 사용하면 "타이머 인터럽트"가 발생하여 다시 준비 상태로 전환되고,
실행 도중 입출력장치를 사용하여 입출력장치의 작업이 끝날 때까지 기다려야 한다면 "대기 상태"로 전환된다.
"대기 상태"로 전환될 때 바로 다음 프로세스를 "실행 상태"로 전환한다.
대기 상태 (blocked)는
입출력장치의 작업을 기다리는 상태를 의미한다.
입출력 작업은 CPU에 비해 처리 속도가 느리기 때문에,
입출력 작업을 요청한 프로세스는 입출력장치가 입출력을 끝낼 때까지 (입출력 완료 인터럽트를 받을 때까지) 기다리기 위해 "대기 상태"로 전환하게 된다.
만약 입출력 작업을 완료하면 해당 프로세스는 다시 "준비 상태"로 CPU의 할당을 기다린다.
종료 상태 (Terminated)는
프로세스가 모든 수행을 마치고 종료된 상태를 의미한다.
프로세스가 종료되면 운영체제는 PCB와 프로세스가 사용한 메모리를 모두 정리한다.
--
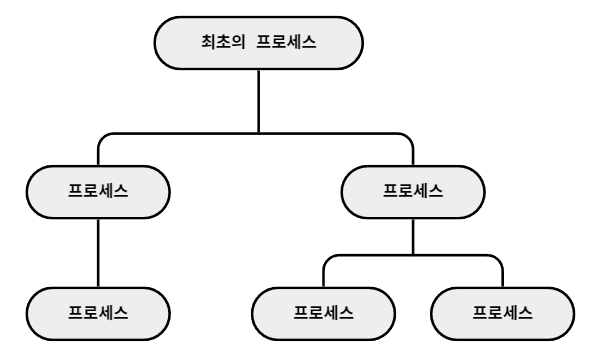
프로세스 계층 구조
--
운영체제는 동시에 실행되는 수많은 프로세스를 계층적으로 관리한다.
프로세스는 실행 도중 시스템 호출을 통해 다른 프로세스를 생성할 수도 있다.
이때 새 프로세스를 생성한 프로세스(기존 프로세스)를 "부모 프로세스",
부모 프로세스에 의해 생성된 프로세스를 "자식 프로세스"라고 부른다.
"자식 프로세스"가 또 다른 "자식 프로세스"를 생성할 수 있다.
"부모 프로세스"와 "자식 프로세스"는 엄연히 다른 프로세스이기 때문에 각자 다른 PID를 가진다. 다만 일부 운영체제는 "자식 프로세스"의 PCB에 "부모 프로세스"의 PID(PPID, Parent PID)를 저장하기도 한다.
많은 운영체제는 이처럼 프로세스가 프로세스를 낳는 계층적인 구조로써 프로세스들을 관리한다.
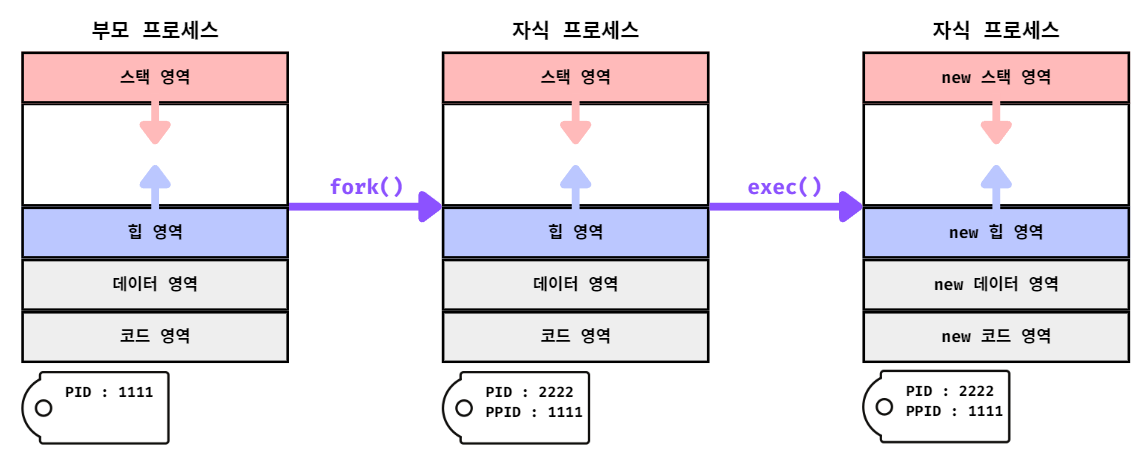
프로세스 생성 기법
부모 프로세스가 자식 프로세스를 생성과는 과정
부모 프로세스는 자신과 똑같은 프로세스를 (fork)를 통해 복사하여 자식 프로세스로 생성
복사된 (자식)프로세스를 (exec)를 통해 자신의 메모리 공간을 다른 프로그램으로 교체
fork와 exec는 시스템 호출이다. fork : 자신의 복사본을 자식 프로세스로 생성 exec : 자신의 메모리 공간을 새로운 프로그램으로 덮음