
이진 탐색 트리란 무엇인가?
이진 탐색 트리 (binary search tree)
--
이진 탐색 트리는
이진 탐색 알고리즘을 기반으로 동적 자료 구조를 생성하는 것으로
정렬된 배열과 달리
효율적인 원소 추가 및 제거뿐 아니라 탐색도 추가로 지원한다.
트리(tree)는
노드의 분기 사슬로 구성된 계층적인 자료 구조다.
트리 노드는
하부 리스트를 가리키는 2가지 next 노드를 허용한다는 점에서 연결 리스트와 차이가 있다.
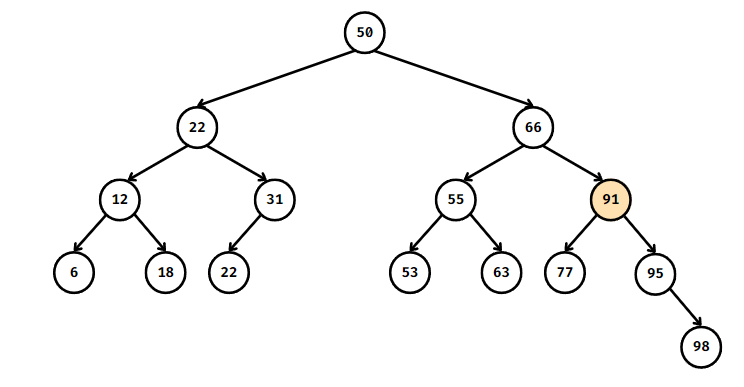
이진 탐색 트리 예시 구조
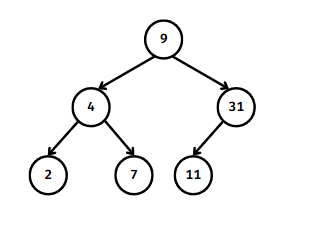
위 그림처럼
노드는 값을 포함하며,
트리의 하위 노드를 가리키는 포인터를 최대 2개 가진다.
여기서 자식이 하나 이상 있는 노드를 '내부(internal, 또는 비단말/비말단/비종단) 노드' 라고 부르며
자식이 없는 노드를 '단말(terminal, 또는 말단/종단) 노드' 또는 '리프(leaf) 노드' 라고 부른다.
- 내부 노드 : 자식이 하나 이상 있는 노드
- 단말 노드 : 자식이 없는 노드
노드는 필요에 따라 다른 정보를 포함할 수 있다.
ex) 노드에 부모를 가리키는 포인터를 저장 (아래에서 위로 탐색도 가능해진다.)
기본적인 이진 탐색 트리 노드의 내부 데이터 구조
public class TreeNode {
int value; // 노드의 값 (int는 예시로 둔 타입으로 다른 타입 가능)
TreeNode left; // 왼쪽 자식 노드
TreeNode right; // 오른쪽 자식 노드
TreeNode parent; // 부모 노드
}
만약 자식 노드가 존재하지 않는다면 null값으로 대체한다.
여기서 추가적으로 부가 데이터를 저장할 수 있으며
개별 값을 저장하고 탐색하는 기능은 유용하지만,
더 자세한 정보를 탐색하기 위한 키로 개별 값을 사용할 수 있으며 자료 구조가 더욱 강력해진다.
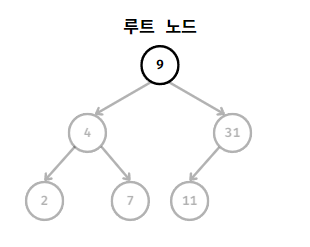
이진 탐색 트리에서 맨 위에 있는 노드를 '루트(root) 노드라고 부르며
이 루트 노드로 부터 시작하여 계층을 내려가면서 가지를 뻗어나간다.
이진 탐색 트리의 구조는
각 노드에서 자식 노드로 뻗어 나갈 때 현재 노드보다 작은 값은 '왼쪽 자식 노드',
크면 '오른쪽 자식 노드'의 구조로 되어 있다.
이진 탐색 트리 속성을 변경하면
중복 값을 허용하는 이진 탐색 트리를 정의할 수도 있다.
--
이진 탐색 트리의 탐색
--
이진 탐색 트리에서는
루트 노드부터 아래로 내려가면서 값을 탐색한다.
각 단계에서는
현재 노드의 값과 목푯값을 비교하여 왼쪽 하위 트리나 오른쪽 하위 트리 중 어느 쪽으로 탐색을 할지 결정한다.
- 현재 노드 값 > 목푯값 : 왼쪽 하위 트리 탐색
- 현재 노드 값 < 목푯값 : 오른쪽 하위 트리 탐색
- 현재 노드 값 = 목푯값 : 탐색 종료
더 이상 탐색해야 할 방향에 자식이 없는 노드에 도달하면 탐색이 종료된다.
아진 탐색 트리를 탐색할 때에는
반복적인 탐색과 재귀적 탐색을 이용하여 구현할 수 있다.
재귀 탐색 코드 예시 [JAVA]
public class TreeNode {
int value;
TreeNode left;
TreeNode right;
TreeNode parent;
public TreeNode(int value) {
this.value = value;
this.left = null;
this.right = null;
this.parent = null;
}
public static TreeNode findValue(TreeNode current, int target) {
if (current == null) { // 현재 노드가 존재하지 않는다면 null 반환
return null;
}
if (current.value == target) { // 현재 노드의 값이 목푯값과 일치하면 해당 노드 반환
return current;
}
if (target < current.value && current.left != null) { // 목푯값이 현재 노드의 값보다 작고 현재 노드에 왼쪽 자식 노드가 존재한다면
return findValue(current.left, target); // 현재 노드의 왼쪽 자식 노드를 가지고 재귀 호출
}
if (target > current.value && current.right != null) { // 목푯값이 현재 노드의 값보다 크고 현재 노드에 오른쪽 자식 노드가 존재한다면
return findValue(current.right, target); // 현재 노드의 오른쪽 자식 노드를 가지고 재귀 호출
}
return null;
}
...
public static void main(String[] args) {
// 예제 트리 생성
TreeNode root = new TreeNode(10);
root.left = new TreeNode(5);
root.right = new TreeNode(15);
root.left.left = new TreeNode(3);
root.left.right = new TreeNode(7);
root.right.left = new TreeNode(12);
root.right.right = new TreeNode(17);
// 값 탐색 예제
TreeNode result = findValue(root, 7);
if (result != null) {
System.out.println("값을 찾았습니다: " + result.value);
} else {
System.out.println("값을 찾지 못했습니다.");
}
}
}
while 탐색 코드 예시 [JAVA]
public class TreeNode {
int value;
TreeNode left;
TreeNode right;
TreeNode parent;
public TreeNode(int value) {
this.value = value;
this.left = null;
this.right = null;
this.parent = null;
}
public static TreeNode findValueItr(TreeNode root, int target) {
TreeNode current = root; // 현재 노드를 따로 복사하여 저장
while (current != null && current.value != target) { // 현재 노드가 null이 아니고 목푯값과 일치하지 않으면 계속 반복
if (target < current.value) { // 목푯값이 현재 노드 값보다 작으면
current = current.left; // 현재 노드를 왼쪽 자식 노드로 변경
} else {
current = current.right; // 현재 노드를 오른쪽 자식 노드로 변경
}
}
return current;
}
}
public class Main {
public static void main(String[] args) {
// 예제 트리 생성
TreeNode root = new TreeNode(10);
root.left = new TreeNode(5);
root.right = new TreeNode(15);
root.left.left = new TreeNode(3);
root.left.right = new TreeNode(7);
root.right.left = new TreeNode(12);
root.right.right = new TreeNode(17);
// 값 탐색 예제
TreeNode result = TreeNode.findValueItr(root, 7);
if (result != null) {
System.out.println("값을 찾았습니다: " + result.value);
} else {
System.out.println("값을 찾지 못했습니다.");
}
}
}
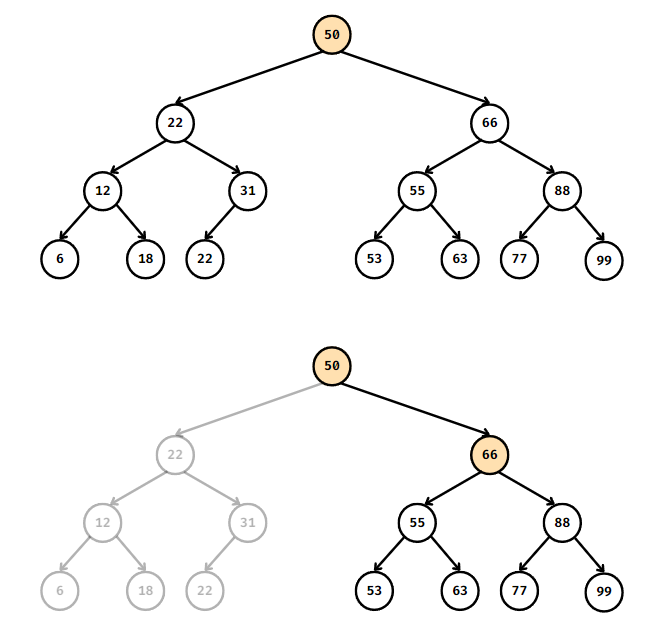
만약 63이라는 값을 탐색하는 것이 목표라고 하면
루트 노드에서 단 한 번의 비교만으로 전체 노드 중의 거의 절반의 노드를 탐색 대상에서 제외할 수 있다.
재귀나 반복 탐색의 계산 비용은
트리에서 목푯값을 찾는 데 필요한 깊이에 비례한다.
즉, 트리가 깊을수록 더 많이 비교하게 되므로
트리 깊이를 최소화해서 탐색 효율성을 높이는 것이 중요하다.
--
이진 탐색 트리 변경하기 (노드 삽입 및 제거)
--
이진 탐색 트리를 사용하거나 변경할 때는
항상 루트 노드에 관심을 두어야 한다.
트리에서 노드를 탐색할 때는 항상 루트 노드에서 시작한다.
처음으로 노드를 트리에 삽입하는 경우
해당 노드를 루트 노드로 만들어야 한다.
노드를 제거할 때는 루트 노드를 특별한 경우로 처리해야 한다.
이러한 처리가 낭비(복잡도가 늘어나고 자료 구조가 추가됨)처럼 보일 수 있지만,
트리의 사용을 더 쉽게 해 주고 루트 노드의 처리를 크게 단순화해 준다.
노드 삽입하기
이진 탐색 트리에 값을 삽입하는 것은 탐색과 기본적으로 같은 알고리즘을 사용한다.
탐색과 삽입 알고리즘의 주된 차이는
삽입 알고리즘은 막다른 골목에 도달한 후
현재 노드의 자식으로 새 노드를 추가한다는 것이다.
새 값이 현재 노드의 값보다 작은 경우에는 왼쪽 자식으로,
그렇지 않으면 오른쪽 자식으로 새 노드를 추가한다.
여기서 중복을 허용하는 트리와 그렇지 않은 트리의 동작 차이를 명확히 볼 수 있다.
중복 값을 허용하는 경우에는
막다른 골목에 도달할 때까지 계속 진행한 다음 새 값을 트리에 삽입하고
중복 값을 허용하지 않는 경우에는
새 값과 일치하는 노드에 저장된 데이터를 대체하거나 추가 정보를 저장할 수 있다.
노드 삽입 과정
1. 트리가 비어 있는지 확인 (tree.root == null)
- 비어 있다면 새 값이 포함된 루트 노드로 생성
- 비어 있지 않으면, 반복(재귀 or while) 시작
2. 반복 내용
- 현재 노드 값이 목푯값(삽입하려는 노드 값)과 동일한지 확인
- 일치하다면 필요에 따라 노드 데이터를 갱신 후 종료
- 일치하지 않다면 두 값의 비교에 따라 왼쪽 자식 노드, 오른쪽 자식 노드 둘 중 삽입할 위치 선택
- 선택한 자식 노드에 자식 노드(다음 노드)가 존재하는지 확인
- 존재하지 않는다면 해당 위치에 삽입하려는 노드 생성
- 존재한다면 해당 노드로 이동 후 위 과정을 다시 반복
노드 제거하기
이진 탐색 트리에서 노드를 제거하는 것은 삽입보다 복잡한 과정이다.
노드를 제거할 때는 3가지 경우를 고려해야 한다.
- 자식이 없는 리프 노드를 제거하는 경우
- 자식이 하나뿐인 내부 노드를 제거하는 경우
- 자식이 둘인 내부 노드를 제거하는 경우
자식의 수가 늘어날수록 작업이 복잡해진다.
1. 리프 노드 제거
리프 노드를 제거하고 해당 리프 노드의 부모 노드의 자식 포인터를 null로 변경하여 해당 노드가 더 이상 존재하지 않음을 표시한다.
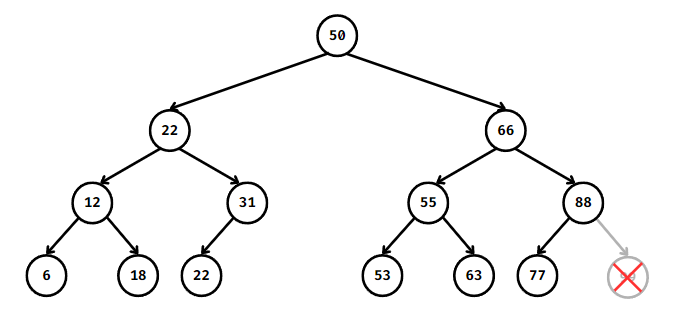
2. 자식 노드가 하나인 내부 노드 제거
제거할 노드의 자식 노드를 제거할 노드의 부모 노드의 자식으로 승격시키고 제거할 노드를 제거한다.
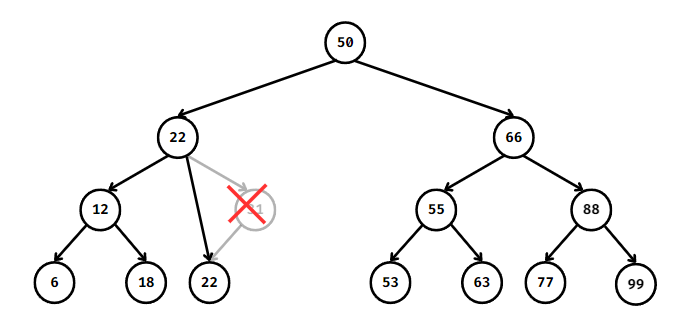
3. 자식 노드가 둘인 내부 노드 제거
이 때는 노드를 제거하거나 자식을 하나 승격시키는 것만으로 충분하지 않다.
(제거할 노드를 제외한 나머지 트리의 무결성을 유지하고 계속 이진 탐색 트리 속성을 따르게 보장해야 한다.)
자식이 둘인 내부 노드를 제거할 때는
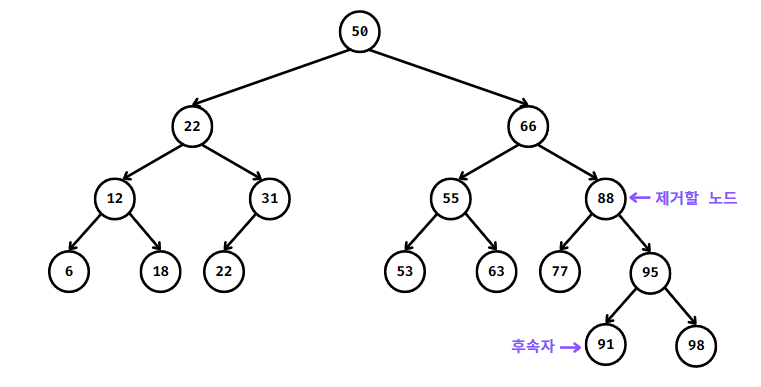
제거할 노드와 교환해도 계속 이진 탐색 트리 속성이 유지될 수 있는 다른 노드와 제거할 노드를 교환한다.
이를 위해서 제거할 노드의 '후속자(successor)'를 찾아야 한다.
후속자(successor)는
정렬된 순서로 노드를 순활할 때 제거할 노드의 바로 다음에 만나게 될 노드를 의미한다.
즉, 제거할 노드의 값보다는 큰 노드들 중에 가장 작은 값을 가진 노드가 후속자이다.
후속자를 찾는 방법은
제거하려는 노드에 자식이 2개인 경우만 고려하므로
후속자는 항상 제거하려는 노드의 오른쪽 하위 트리에서 찾을 수 있으며
구체적으로는 오른쪽 하위 트리에서 가장 왼쪽에 위치하고 있는 노드다.
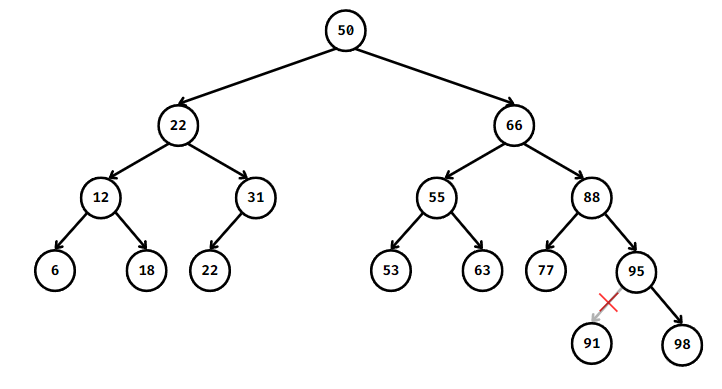
1. 88값을 가진 내부 노드를 제거하고자 하면 91값을 가진 노드가 후속자다.
정리
특정 노드를 제거할 때에는
- 리프 노드를 제거하는지
- 자식이 하나뿐인 내부 노드를 제거하는지
- 자식이 둘인 내부 노드를 제거하는지
이 3 가지 경우를 고려해야 한다.
노드 제거 메서드 예시 코드 [JAVA]
public class BSTDeletion {
public static void removeTreeNode(BinarySearchTree tree, TreeNode node) {
// 루트 노드가 존재하는지 확인
if (tree.root == null || node == null) {
return;
}
// 리프 노드 제거하는 경우
if (node.left == null && node.right == null) {
if (node.parent == null) { // 해당 리프 노드의 부모가 없다면 (=루트 노드)
tree.root = null;
} else if (node.parent.left == node) {
node.parent.left = null;
} else {
node.parent.right = null;
}
return;
}
// 자식이 하나인 내부 노드 제거하는 경우
if (node.left == null || node.right == null) {
TreeNode child = node.left; // 자식 노드를 따로 빼놓는다.
if (node.left == null) {
child = node.right;
}
child.parent = node.parent; // 부모 노드를 따로 빼놓는다.
if (node.parent == null) {
tree.root = child;
} else if (node.parent.left == node) {
node.parent.left = child;
} else {
node.parent.right = child;
}
return;
}
// 자식이 둘인 내부 노드 제거하는 경우
// 후속자를 찾고, 트리에서 제거
TreeNode successor = node.right;
while (successor.left != null) {
successor = successor.left;
}
removeTreeNode(tree, successor);
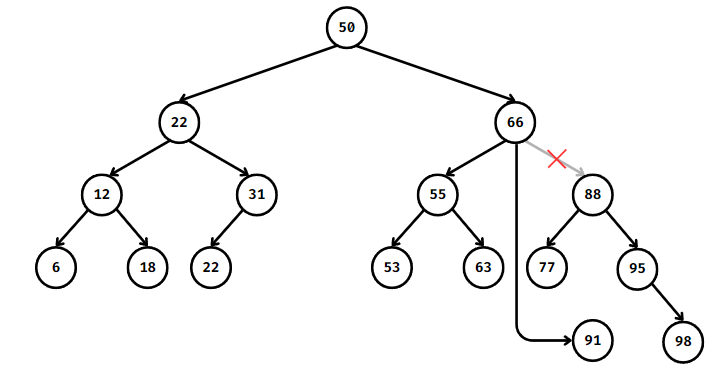
// 후속자를 제거할 노드 위치에 삽입
if (node.parent == null) { // 제거된 노드의 부모를 수정 (자식 포인터를 후속자로 설정)
tree.root = successor;
} else if (node.parent.left == node) {
node.parent.left = successor;
} else {
node.parent.right = successor;
}
successor.parent = node.parent; // 후속자의 부모 포인터를 새로운 부모로 설정
successor.left = node.left; // 후속자의 왼쪽과 오른쪽 자식 사이의 링크를 설정
node.left.parent = successor;
successor.right = node.right;
if (node.right != null) {
node.right.parent = successor;
}
}
}
위 코드보다 더 짧은 구현도 가능하지만,
명시적으로 각 경우를 분할하면 알고리즘의 복잡성을 명확하게 이해할 수 있다.
--
균형이 맞지 않는 트리의 위험성
--
이진 탐색 트리에서
탐색, 추가 및 제거를 수행하는 데 걸리는 시간은
최악의 경우 트리의 깊이에 비례하므로
깊이가 너무 깊지 않은 트리에서는 이러한 작업이 매우 효율적으로 이뤄진다.
완전 균형(prefectly balanced) 트리는
모든 노드에서 오른쪽 하위 트리가 왼쪽 하위 트리와 동일한 수의 노드를 포함하는 경우다.
이진 탐색 트리는 완벽하지 않더라도
어느 정도만 균형이 맞으면 여전히 효율적이다.
하지만 트리가 균형이 잘 맞지 않으면 원소 수에 비례해 트리 깊이가 선형적으로 증가할 수 있다.
극단적인 경우 모든 노드가 같은 방향의 자식만 가지는 경우다.
(이러한 경우 정렬된 연결 리스트와 별반 다를 것이 없다.)
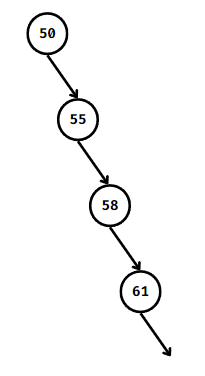
--
'CS > 자료구조' 카테고리의 다른 글
| 우선순위 큐와 힙 (0) | 2024.08.08 |
|---|---|
| 트라이와 적응형 자료 구조 (0) | 2024.08.06 |
| 스택과 큐 (+ 깊이 우선 탐색, 너비 우선 탐색) (0) | 2024.08.03 |
| 동적 자료 구조 (+ 연결 리스트) (0) | 2024.08.02 |
| 이진 탐색 (+ 선형 스캔) (0) | 2024.08.01 |
이진 탐색 트리란 무엇인가?
이진 탐색 트리 (binary search tree)
--
이진 탐색 트리는
이진 탐색 알고리즘을 기반으로 동적 자료 구조를 생성하는 것으로
정렬된 배열과 달리
효율적인 원소 추가 및 제거뿐 아니라 탐색도 추가로 지원한다.
트리(tree)는
노드의 분기 사슬로 구성된 계층적인 자료 구조다.
트리 노드는
하부 리스트를 가리키는 2가지 next 노드를 허용한다는 점에서 연결 리스트와 차이가 있다.
이진 탐색 트리 예시 구조
위 그림처럼
노드는 값을 포함하며,
트리의 하위 노드를 가리키는 포인터를 최대 2개 가진다.
여기서 자식이 하나 이상 있는 노드를 '내부(internal, 또는 비단말/비말단/비종단) 노드' 라고 부르며
자식이 없는 노드를 '단말(terminal, 또는 말단/종단) 노드' 또는 '리프(leaf) 노드' 라고 부른다.
- 내부 노드 : 자식이 하나 이상 있는 노드
- 단말 노드 : 자식이 없는 노드
노드는 필요에 따라 다른 정보를 포함할 수 있다.
ex) 노드에 부모를 가리키는 포인터를 저장 (아래에서 위로 탐색도 가능해진다.)
기본적인 이진 탐색 트리 노드의 내부 데이터 구조
public class TreeNode {
int value; // 노드의 값 (int는 예시로 둔 타입으로 다른 타입 가능)
TreeNode left; // 왼쪽 자식 노드
TreeNode right; // 오른쪽 자식 노드
TreeNode parent; // 부모 노드
}
만약 자식 노드가 존재하지 않는다면 null값으로 대체한다.
여기서 추가적으로 부가 데이터를 저장할 수 있으며
개별 값을 저장하고 탐색하는 기능은 유용하지만,
더 자세한 정보를 탐색하기 위한 키로 개별 값을 사용할 수 있으며 자료 구조가 더욱 강력해진다.
이진 탐색 트리에서 맨 위에 있는 노드를 '루트(root) 노드라고 부르며
이 루트 노드로 부터 시작하여 계층을 내려가면서 가지를 뻗어나간다.
이진 탐색 트리의 구조는
각 노드에서 자식 노드로 뻗어 나갈 때 현재 노드보다 작은 값은 '왼쪽 자식 노드',
크면 '오른쪽 자식 노드'의 구조로 되어 있다.
이진 탐색 트리 속성을 변경하면
중복 값을 허용하는 이진 탐색 트리를 정의할 수도 있다.
--
이진 탐색 트리의 탐색
--
이진 탐색 트리에서는
루트 노드부터 아래로 내려가면서 값을 탐색한다.
각 단계에서는
현재 노드의 값과 목푯값을 비교하여 왼쪽 하위 트리나 오른쪽 하위 트리 중 어느 쪽으로 탐색을 할지 결정한다.
- 현재 노드 값 > 목푯값 : 왼쪽 하위 트리 탐색
- 현재 노드 값 < 목푯값 : 오른쪽 하위 트리 탐색
- 현재 노드 값 = 목푯값 : 탐색 종료
더 이상 탐색해야 할 방향에 자식이 없는 노드에 도달하면 탐색이 종료된다.
아진 탐색 트리를 탐색할 때에는
반복적인 탐색과 재귀적 탐색을 이용하여 구현할 수 있다.
재귀 탐색 코드 예시 [JAVA]
public class TreeNode {
int value;
TreeNode left;
TreeNode right;
TreeNode parent;
public TreeNode(int value) {
this.value = value;
this.left = null;
this.right = null;
this.parent = null;
}
public static TreeNode findValue(TreeNode current, int target) {
if (current == null) { // 현재 노드가 존재하지 않는다면 null 반환
return null;
}
if (current.value == target) { // 현재 노드의 값이 목푯값과 일치하면 해당 노드 반환
return current;
}
if (target < current.value && current.left != null) { // 목푯값이 현재 노드의 값보다 작고 현재 노드에 왼쪽 자식 노드가 존재한다면
return findValue(current.left, target); // 현재 노드의 왼쪽 자식 노드를 가지고 재귀 호출
}
if (target > current.value && current.right != null) { // 목푯값이 현재 노드의 값보다 크고 현재 노드에 오른쪽 자식 노드가 존재한다면
return findValue(current.right, target); // 현재 노드의 오른쪽 자식 노드를 가지고 재귀 호출
}
return null;
}
...
public static void main(String[] args) {
// 예제 트리 생성
TreeNode root = new TreeNode(10);
root.left = new TreeNode(5);
root.right = new TreeNode(15);
root.left.left = new TreeNode(3);
root.left.right = new TreeNode(7);
root.right.left = new TreeNode(12);
root.right.right = new TreeNode(17);
// 값 탐색 예제
TreeNode result = findValue(root, 7);
if (result != null) {
System.out.println("값을 찾았습니다: " + result.value);
} else {
System.out.println("값을 찾지 못했습니다.");
}
}
}
while 탐색 코드 예시 [JAVA]
public class TreeNode {
int value;
TreeNode left;
TreeNode right;
TreeNode parent;
public TreeNode(int value) {
this.value = value;
this.left = null;
this.right = null;
this.parent = null;
}
public static TreeNode findValueItr(TreeNode root, int target) {
TreeNode current = root; // 현재 노드를 따로 복사하여 저장
while (current != null && current.value != target) { // 현재 노드가 null이 아니고 목푯값과 일치하지 않으면 계속 반복
if (target < current.value) { // 목푯값이 현재 노드 값보다 작으면
current = current.left; // 현재 노드를 왼쪽 자식 노드로 변경
} else {
current = current.right; // 현재 노드를 오른쪽 자식 노드로 변경
}
}
return current;
}
}
public class Main {
public static void main(String[] args) {
// 예제 트리 생성
TreeNode root = new TreeNode(10);
root.left = new TreeNode(5);
root.right = new TreeNode(15);
root.left.left = new TreeNode(3);
root.left.right = new TreeNode(7);
root.right.left = new TreeNode(12);
root.right.right = new TreeNode(17);
// 값 탐색 예제
TreeNode result = TreeNode.findValueItr(root, 7);
if (result != null) {
System.out.println("값을 찾았습니다: " + result.value);
} else {
System.out.println("값을 찾지 못했습니다.");
}
}
}
만약 63이라는 값을 탐색하는 것이 목표라고 하면
루트 노드에서 단 한 번의 비교만으로 전체 노드 중의 거의 절반의 노드를 탐색 대상에서 제외할 수 있다.
재귀나 반복 탐색의 계산 비용은
트리에서 목푯값을 찾는 데 필요한 깊이에 비례한다.
즉, 트리가 깊을수록 더 많이 비교하게 되므로
트리 깊이를 최소화해서 탐색 효율성을 높이는 것이 중요하다.
--
이진 탐색 트리 변경하기 (노드 삽입 및 제거)
--
이진 탐색 트리를 사용하거나 변경할 때는
항상 루트 노드에 관심을 두어야 한다.
트리에서 노드를 탐색할 때는 항상 루트 노드에서 시작한다.
처음으로 노드를 트리에 삽입하는 경우
해당 노드를 루트 노드로 만들어야 한다.
노드를 제거할 때는 루트 노드를 특별한 경우로 처리해야 한다.
이러한 처리가 낭비(복잡도가 늘어나고 자료 구조가 추가됨)처럼 보일 수 있지만,
트리의 사용을 더 쉽게 해 주고 루트 노드의 처리를 크게 단순화해 준다.
노드 삽입하기
이진 탐색 트리에 값을 삽입하는 것은 탐색과 기본적으로 같은 알고리즘을 사용한다.
탐색과 삽입 알고리즘의 주된 차이는
삽입 알고리즘은 막다른 골목에 도달한 후
현재 노드의 자식으로 새 노드를 추가한다는 것이다.
새 값이 현재 노드의 값보다 작은 경우에는 왼쪽 자식으로,
그렇지 않으면 오른쪽 자식으로 새 노드를 추가한다.
여기서 중복을 허용하는 트리와 그렇지 않은 트리의 동작 차이를 명확히 볼 수 있다.
중복 값을 허용하는 경우에는
막다른 골목에 도달할 때까지 계속 진행한 다음 새 값을 트리에 삽입하고
중복 값을 허용하지 않는 경우에는
새 값과 일치하는 노드에 저장된 데이터를 대체하거나 추가 정보를 저장할 수 있다.
노드 삽입 과정
1. 트리가 비어 있는지 확인 (tree.root == null)
- 비어 있다면 새 값이 포함된 루트 노드로 생성
- 비어 있지 않으면, 반복(재귀 or while) 시작
2. 반복 내용
- 현재 노드 값이 목푯값(삽입하려는 노드 값)과 동일한지 확인
- 일치하다면 필요에 따라 노드 데이터를 갱신 후 종료
- 일치하지 않다면 두 값의 비교에 따라 왼쪽 자식 노드, 오른쪽 자식 노드 둘 중 삽입할 위치 선택
- 선택한 자식 노드에 자식 노드(다음 노드)가 존재하는지 확인
- 존재하지 않는다면 해당 위치에 삽입하려는 노드 생성
- 존재한다면 해당 노드로 이동 후 위 과정을 다시 반복
노드 제거하기
이진 탐색 트리에서 노드를 제거하는 것은 삽입보다 복잡한 과정이다.
노드를 제거할 때는 3가지 경우를 고려해야 한다.
- 자식이 없는 리프 노드를 제거하는 경우
- 자식이 하나뿐인 내부 노드를 제거하는 경우
- 자식이 둘인 내부 노드를 제거하는 경우
자식의 수가 늘어날수록 작업이 복잡해진다.
1. 리프 노드 제거
리프 노드를 제거하고 해당 리프 노드의 부모 노드의 자식 포인터를 null로 변경하여 해당 노드가 더 이상 존재하지 않음을 표시한다.
2. 자식 노드가 하나인 내부 노드 제거
제거할 노드의 자식 노드를 제거할 노드의 부모 노드의 자식으로 승격시키고 제거할 노드를 제거한다.
3. 자식 노드가 둘인 내부 노드 제거
이 때는 노드를 제거하거나 자식을 하나 승격시키는 것만으로 충분하지 않다.
(제거할 노드를 제외한 나머지 트리의 무결성을 유지하고 계속 이진 탐색 트리 속성을 따르게 보장해야 한다.)
자식이 둘인 내부 노드를 제거할 때는
제거할 노드와 교환해도 계속 이진 탐색 트리 속성이 유지될 수 있는 다른 노드와 제거할 노드를 교환한다.
이를 위해서 제거할 노드의 '후속자(successor)'를 찾아야 한다.
후속자(successor)는
정렬된 순서로 노드를 순활할 때 제거할 노드의 바로 다음에 만나게 될 노드를 의미한다.
즉, 제거할 노드의 값보다는 큰 노드들 중에 가장 작은 값을 가진 노드가 후속자이다.
후속자를 찾는 방법은
제거하려는 노드에 자식이 2개인 경우만 고려하므로
후속자는 항상 제거하려는 노드의 오른쪽 하위 트리에서 찾을 수 있으며
구체적으로는 오른쪽 하위 트리에서 가장 왼쪽에 위치하고 있는 노드다.
1. 88값을 가진 내부 노드를 제거하고자 하면 91값을 가진 노드가 후속자다.
정리
특정 노드를 제거할 때에는
- 리프 노드를 제거하는지
- 자식이 하나뿐인 내부 노드를 제거하는지
- 자식이 둘인 내부 노드를 제거하는지
이 3 가지 경우를 고려해야 한다.
노드 제거 메서드 예시 코드 [JAVA]
public class BSTDeletion {
public static void removeTreeNode(BinarySearchTree tree, TreeNode node) {
// 루트 노드가 존재하는지 확인
if (tree.root == null || node == null) {
return;
}
// 리프 노드 제거하는 경우
if (node.left == null && node.right == null) {
if (node.parent == null) { // 해당 리프 노드의 부모가 없다면 (=루트 노드)
tree.root = null;
} else if (node.parent.left == node) {
node.parent.left = null;
} else {
node.parent.right = null;
}
return;
}
// 자식이 하나인 내부 노드 제거하는 경우
if (node.left == null || node.right == null) {
TreeNode child = node.left; // 자식 노드를 따로 빼놓는다.
if (node.left == null) {
child = node.right;
}
child.parent = node.parent; // 부모 노드를 따로 빼놓는다.
if (node.parent == null) {
tree.root = child;
} else if (node.parent.left == node) {
node.parent.left = child;
} else {
node.parent.right = child;
}
return;
}
// 자식이 둘인 내부 노드 제거하는 경우
// 후속자를 찾고, 트리에서 제거
TreeNode successor = node.right;
while (successor.left != null) {
successor = successor.left;
}
removeTreeNode(tree, successor);
// 후속자를 제거할 노드 위치에 삽입
if (node.parent == null) { // 제거된 노드의 부모를 수정 (자식 포인터를 후속자로 설정)
tree.root = successor;
} else if (node.parent.left == node) {
node.parent.left = successor;
} else {
node.parent.right = successor;
}
successor.parent = node.parent; // 후속자의 부모 포인터를 새로운 부모로 설정
successor.left = node.left; // 후속자의 왼쪽과 오른쪽 자식 사이의 링크를 설정
node.left.parent = successor;
successor.right = node.right;
if (node.right != null) {
node.right.parent = successor;
}
}
}
위 코드보다 더 짧은 구현도 가능하지만,
명시적으로 각 경우를 분할하면 알고리즘의 복잡성을 명확하게 이해할 수 있다.
--
균형이 맞지 않는 트리의 위험성
--
이진 탐색 트리에서
탐색, 추가 및 제거를 수행하는 데 걸리는 시간은
최악의 경우 트리의 깊이에 비례하므로
깊이가 너무 깊지 않은 트리에서는 이러한 작업이 매우 효율적으로 이뤄진다.
완전 균형(prefectly balanced) 트리는
모든 노드에서 오른쪽 하위 트리가 왼쪽 하위 트리와 동일한 수의 노드를 포함하는 경우다.
이진 탐색 트리는 완벽하지 않더라도
어느 정도만 균형이 맞으면 여전히 효율적이다.
하지만 트리가 균형이 잘 맞지 않으면 원소 수에 비례해 트리 깊이가 선형적으로 증가할 수 있다.
극단적인 경우 모든 노드가 같은 방향의 자식만 가지는 경우다.
(이러한 경우 정렬된 연결 리스트와 별반 다를 것이 없다.)
--
'CS > 자료구조' 카테고리의 다른 글
| 우선순위 큐와 힙 (0) | 2024.08.08 |
|---|---|
| 트라이와 적응형 자료 구조 (0) | 2024.08.06 |
| 스택과 큐 (+ 깊이 우선 탐색, 너비 우선 탐색) (0) | 2024.08.03 |
| 동적 자료 구조 (+ 연결 리스트) (0) | 2024.08.02 |
| 이진 탐색 (+ 선형 스캔) (0) | 2024.08.01 |