
동적 자료 구조란 무엇인가?
배열의 한계
--
배열은 메모리 접근 속도가 빠르고, 구조가 단순하여
기본적인 데이터 저장 용도로 유용하지만
다방면으로 사용하기에는 한계가 존재한다.
여러 한계들이 존재하지만 그중에 중요한 것은
배열을 처음 생성할 때 정해진 해당 배열의 크기와 메모리 레이아웃은 고정이 되어 변경이 불가능하다.
메모리 레이아웃이란
메모리의 구조와 분포를 나타내는 것으로
간단하게 메모리의 공간(영역)으로 생각하면 된다.
즉, 이미 생성한 배열의 크기보다 큰 데이터를 담으려면(저장) 해당 크기에 알맞은 배열을 새로 생성해서 할당해야 한다.
- 배열의 크기가 '5'지만 총 6개의 데이터를 담아야 하는 경우
이러한 단점을 보안하기 위해 현대적인 프로그래밍 언어에서는
원소를 추가하면 크기가 커지고 원소를 제거하면 크기가 작아지는 동적인 배열을 제공하지만
내부적으로 동작하는 것을 보면 결국 새로운 배열을 생성해서 기존 배열의 값을 복사하는 과정이 숨겨져 있기 때문에
결과적으로는 비슷하다고 볼 수 있다.
그래서 이러한 경우 동적 자료 구조를 사용하여 더욱 효율적으로 대처할 수 있다.
배열의 한계 및 단점에 대한 일부분 정리
1. 고정된 크기
- 배열의 크기는 선언 시에 정해지며, 이후에는 변경이 불가능하다.
배열의 크기를 동적으로 조절할 수 없기 때문에, 초기 크기를 지정할 때 사용할 데이터 양을 예측하여 지정해야 한다.
생성한 배열에서 사용하는 공간이 적다면 메모리 낭비가 될 수 있으며
생성한 배열의 크기보다 사용해야 하는 공간이 많아야 한다면 다시 배열을 생성해야 한다.
2. 삽입과 삭제의 비효율성
- 배열의 중간에 요소를 삽입 또는 삭제할 때, 해당 위치 이후의 모든 요소의 위치를 이동시켜주어야 한다.
3. 메모리 연속성 요구
- 배열은 연속된 메모리 공간이 필요하다.
큰 배열을 할당할 때, 연속된 충분한 메모리 공간을 찾기 어려울 수 있다.
예시로 총 메모리 공간이 [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ] 이렇게 존재한다고 가정하고
이 중에서 [1], [3], [6], [9] 메모리 공간은 이미 사용 중이라고 하자. [ 0,1, 2,3, 4, 5,6, 7, 8,9]
이때 배열의 크기가 4인 배열을 생성하려고 하지만 메모리 공간에서 연속된 4개의 공간이 존재하지 않기 때문에 불가능하다.
4. 동종 데이터만 저장 가능
- 배열은 동일한 데이터 타입의 요소들만 저장할 수 있다.
5. 크기 제한
- 배열의 최대 크기는 시스템의 메모리 크기와 컴파일러의 제한에 의해 자동으로 결정된다.
--
동적 자료 구조
--
동적 자료 구조는
데이터가 변경될 때 구조도 변경되는 것이다.
(실행 중에 크기가 변경될 수 있는 자료구조)
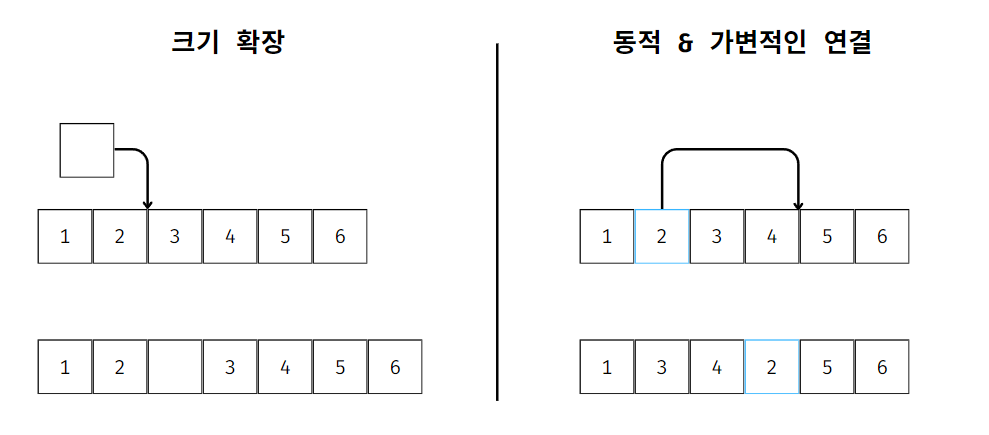
여기서 구조가 변경된다는 것은
해당 구조 자체의 크기를 확장 및 축소하거나 각각의 공간들이 동적이고 가변적인 연결을 만드는 것 등이 포함된다.
동적 자료 구조 종류
- 연결 리스트
- 스택
- 큐
- 트리
- 그래프
- 해시 테이블
등이 존재한다.
--
연결 리스트 (Linked List)
--
연결 리스트는
동적 자료 구조에서 가장 간단한 구조이며
배열과 밀접한 관계로 여러 값을 저장하는 자료 구조다.
다만 배열과 다르게 연결 리스트는 포인터(다른 변수나 메모리 위치(주소)를 가리키는 변수)로 연결된 노드의 사슬로 구성되어 있다.
즉, 배열은 각 메모리 공간에 값만 저장하고 있지만
연결 리스트는 각 메모리 공간에 값과 포인터를 가지고 있는 노드(객체)를 저장하고 있다.
그리고 포인터는 다음 노드를 가리키고 있기 때문에 포인터를 통해 다른 노드와 연결되어 있다고 볼 수 있다.
기본적인 노드(객체) 구조
- 변수 (값)
- 포인터 (다음 노드의 위치(주소))
class Node {
int data; // 데이터(값) / int는 예시로 둔 것이며 다른 타입 또한 가능하다.
Node next; // 포인터
}

위 그림이 연결 리스트를 포인터로 연결한 노드를 표현한 그림이다.
상자에 담긴 숫자가 값이고
화살표는 다음 노드를 가리키는 포인터다.
리스트의 끝에 역슬래시(\)는 NULL값을 의미하며 리스트의 끝을 의미한다.
즉, 리스트의 마지막 노드에 있는 포인터는 다음 노드를 가리키지 않는다는 의미이기도 하다.
조금 더 구체적으로 배열과 연결 리스트를 구분해 보자.
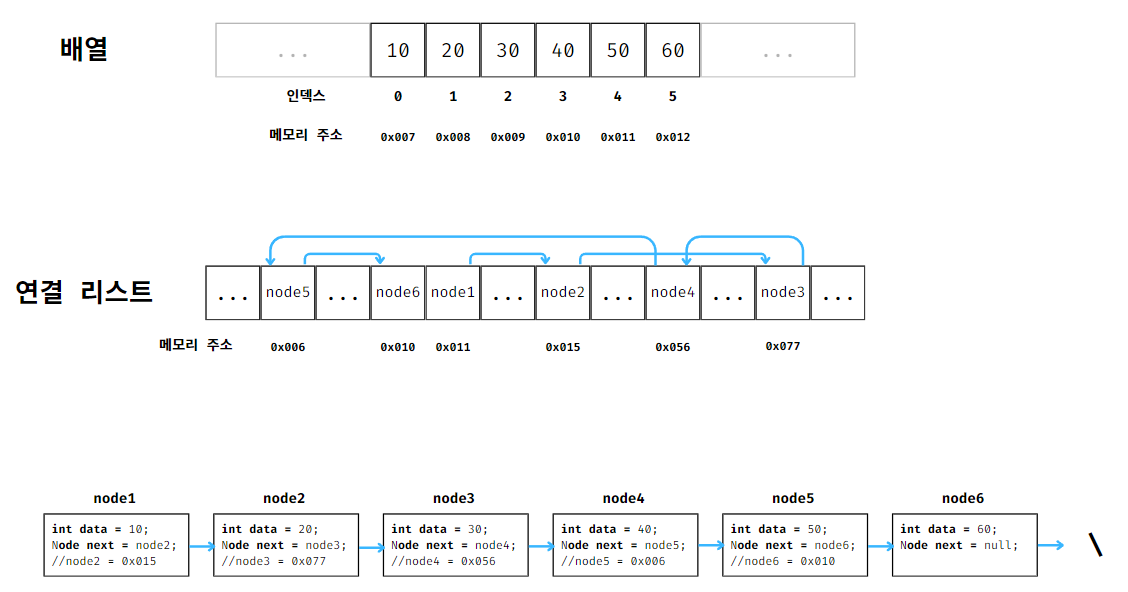
배열 같은 경우 메모리 공간이 연속적이지만
연결 리스트는 메모리 공간이 연속적이지 않아도 된다.
이는 포인터를 통해 다음 노드를 가리키므로 연속적이지 않아도 다음 메모리를 찾아갈 수 있기 때문이다.
이러한 특성 때문에 동적으로 연결 리스트의 크기를 확장 및 축소도 가능해진다.
다만 배열과 달리 각 원소에 포인터도 포함하므로, 배열보다 더 많은 메모리를 사용하게 된다.
하지만 포인터가 제공하는 유연성을 위해서 메모리 사용량 증가를 감수할 가치가 있는 경우가 있기 때문에 사용한다.
프로그램은 일반적으로 연결 리스트의 시작점이자 머리(head)인 하나의 포인터를 유지하면서 연결 리스트를 저장한다.
그 후, 머리(head)에서 시작하여 포인터를 통해 노드를 반복함으로써 리스트의 모든 원소를 접근할 수 있다.
연결 리스트 클래스 예시 코드 [JAVA]
class LinkedList {
Node head; // 노드의 머리 (시작 지점) = 시작 지점 노드를 가리키는 포인터
// 노드를 리스트의 끝에 추가하는 메서드
public void add(int data) {
Node newNode = new Node(data);
if (head == null) { // 만약 노드가 존재하지 않으면
head = newNode; // head 노드에 저장
} else { // 기존 노드가 존재한다면
Node current = head;
while (current.next != null) { // head 노드부터 다음 노드가 없을 때까지 반복
current = current.next;
}
current.next = newNode; // 다음 노드가 없는 위치에 노드 추가
}
}
// 특정 값을 가진 노드를 찾는 메서드
public Node findNode(int value) {
Node current = head; // head 노드
while (current != null) { // 노드가 null이 될 때까지 반복 (끝까지 반복)
if (current.data == value) { // 현재 노드의 값이 목푯값과 동일하면
return current; // 해당 노드 반환
}
current = current.next; // 동일하지 않으면 다음 노드로 이동
}
return null; // 값을 가진 노드를 찾지 못한 경우 null 반환
}
// 연결 리스트의 모든 노드 원소에 접근하여 출력하는 메서드
public void printAllNodes() {
Node current = head;
while (current != null) {
System.out.print(current.data + " -> ");
current = current.next;
}
System.out.println("null");
}
}public class Main {
public static void main(String[] args) {
LinkedList list = new LinkedList();
// 리스트에 노드 추가
list.add(10);
list.add(20);
list.add(30);
list.add(40);
// 리스트 출력
list.printAllNodes(); // 출력: 10 -> 20 -> 30 -> 40 -> null
// 특정 값을 가진 노드를 찾는 메서드 호출
int valueToFind = 30;
Node node = list.findNode(valueToFind);
if (node != null) {
System.out.println("Node with value " + valueToFind + " found: " + node.data);
} else {
System.out.println("Node with value " + valueToFind + " not found");
}
}
}
위 코드로 특정 값을 탐색하는 것을 보면
트레이드 오프(trade-off) 관계가 보인다.
트레이드 오프(trade-off)란
하나의 선택이나 결정이 다른 이점을 희생시키는 상황을 의미한다.
예시
시간 복잡도 vs 공간 복잡도
ex) 알고리즘 설계 시 실행 시간을 줄이기 위해 더 많은 메모리를 사용하는 경우
응답 시간 vs 처리량
ex) 실시간 시스템에서 빠른 응답을 위해 시스템의 전체적인 처리량을 감소되는 경우
자료 구조에서는
대부분 '복잡성', '효율성', '사용 패턴' 사이에 트레이트 오프 관계가 있다.
그래서 상황에 알맞은 자료 구조를 사용해야 한다.
연결 리스트는 관심 있는 원소에 도달할 때까지 시작 시점부터 반복하여 탐색해야 한다.
즉, 원소 접근의 부가 비용을 증가시키는 대신 전체 자료 구조의 유연성이 상당히 증가한다.
--
연결 리스트에 대한 연산 (원소 삽입 & 삭제)
--
원소를 삽입할 때에는 두 단계를 걸쳐서 삽입하면 된다.
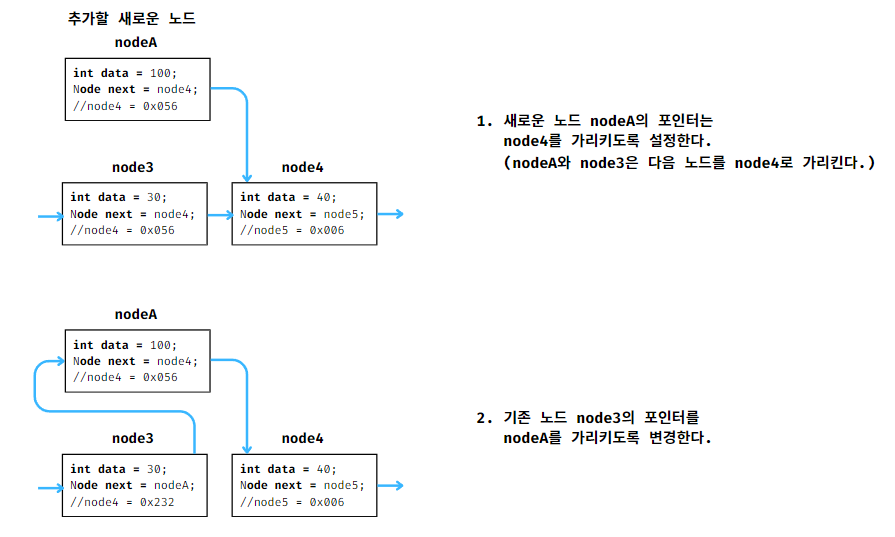
여기서 이 과정이 매우 중요한데
2번을 1번 보다 먼저 수행하게 되면 node4의 위치를 가리키는 포인터가 없어지므로 node4의 위치를 알 수 없게 되어
nodeA의 포인터를 node4로 설정할 수 없게 된다.
연결 리스트의 머리 노드 앞에 노드를 삽입하는 경우에는
머리 포인터 자체를 갱신해줘야 한다.
그렇지 않으면 계속 이전의 머리 노드를 첫 번째 원소로 접근하기 때문이다.
원소를 제거할 때에는 이전 원소의 포인터의 값을 제거할 원소의 포인터 값으로 변경해 주면 된다.

자바같이 가비지 컬렉션 기능이 존재한다면 사용하지 않는 데이터들은 자동으로 메모리에서 해제하지만
이러한 기능이 없는 언어라면 1번 과정을 하고 node3 원소를 메모리에서 해제해 주는 작업이 추가로 필요하다.
이렇게 삽입 & 삭제를 할 때
배열 같은 경우 새로 배열을 생성해야 하는 경우가 발생하거나 각 값들을 한 칸씩 이동시켜야 하는 경우가 생길 수 있기 때문에 비용이 많이 들 수 있다.
하지만 연결 리스트를 사용하게 되면 상대적으로 비용을 줄일 수 있게 된다.
--
이중 연결 리스트
--
이중 연결 리스트는
기존 연결 리스트에서 각 노드에 이전 노드를 가리키는 포인터가 포함되어 있다.
즉, 이중 연결 리스트에서 사용하는 노드에는 '값', '다음 노드를 가리키는 포인터', '이전 노드를 가리키는 포인터'를 가진다.
class Node {
int data; // 데이터(값) / int는 예시로 둔 것이며 다른 타입 또한 가능하다.
Node next; // 다음 노드를 가리키는 포인터
Node previous // 이전 노드를 가리키는 포인터
}

--
'CS > 자료구조' 카테고리의 다른 글
| 이진 탐색 트리 (0) | 2024.08.05 |
|---|---|
| 스택과 큐 (+ 깊이 우선 탐색, 너비 우선 탐색) (0) | 2024.08.03 |
| 이진 탐색 (+ 선형 스캔) (0) | 2024.08.01 |
| 데이터를 메모리에 저장하기 ( + 배열의 삽입 정렬 ) (0) | 2024.07.31 |
| 자료구조란? (0) | 2024.07.30 |