
해시 테이블이란 무엇일까?
키를 사용한 저장 및 탐색
--
정수 값을 효율적으로 탐색하기 위한 이상적인 인덱싱 방법을 생각해 보면
모든 값에 대해 개별적으로 배열 상자를 유지하고,
값을 사용하여 해당 상자를 인덱싱하는 것이다.
인덱싱(Indexing)은
데이터를 효율적으로 검색하고 조회하기 위해
데이터의 위치나 상태를 체계적으로 정리하는 과정을 의미한다.
예시) 도서관에서 책을 쉽게 찾기 위해 책의 위치를 정리하는 것
간단한 예시를 들면
값 9를 삽입하기 위해 인덱스가 9인 상자에 넣는다.
다만 이러한 자료 구조에는 존재할 수 있는 모든 키의 배열을 유지하기 위해 엄청난 비용이 들게 된다.
예시로 16자리 신용카드 번호를 모두 저장하려면 10^16개의 상자가 필요하게 된다. (아주 큰 메모리가 필요)
여기서 더 큰 문제는 해당 모든 상자를 사용할 가능성이 매우 낮아 메모리 낭비가 된다.
그리고 키 값이 정수가 아니면 사용할 수가 없다.
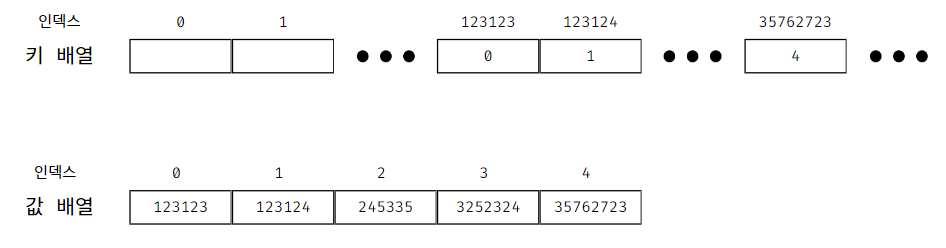
컴퓨터 프로그램은 종종 키(key)를 사용하여 레코드를 식별한다.
키(key)는
데이터와 함께 저장되거나
데이터로부터 유도된 단일 값이며,
레코드를 식별할 때 키를 사용할 수 있다.
즉, 데이터베이스에서 특정 데이터를 고유하게 식별할 수 있는 값을 의미한다.
데이터베이스의 테이블 내의 특정 컬럼에서 유일한 값을 가지고 있으며
이를 통해 데이터의 중복을 피하고 데이터 검색 속도를 높인다.
레코드(Record)는
데이터베이스(테이블)에서 하나의 행(row) 또는 엔트리(entry)를 의미한다.
레코드는 튜플(Tuple)이라고도 부른다.
--
해시 테이블(Hash Table)
--
해시 테이블은
수학 함수를 사용해서 데이터의 위치를 알려주는 자료 구조로
특히 정보를 탐색해서 빠르게 읽고 싶은 순수한 저장 용도의 경우에 해시 테이블이 유용하다.
수학적인 매핑을 사용해 키 공간을 압축한다.
키(key)를 테이블상 위치(해시 값)로 매핑하는 해시 함수를 사용해서 큰 키 공간을 작은 영역으로 축소시킨다.
즉, 키(key)와 값(value)을 매핑하여 데이터를 효율적으로 저장하고 검색할 수 있는 구조다.
이 매핑을 통해서 키를 배열로 사용했을 경우의 두 가지 문제를 해결할 수 있다.
- 키를 저장하는 아주 많은 상자가 필요하지 않다 (값의 개수와 키의 개수가 동일)
- 키에 정수가 아닌 값도 사용이 가능
정수로 이루어진 키(key)에 대해 간단한 해시 함수를 정의하는 방법
- 키 = k = 해시 테이블에 저장하려는 데이터의 고유한 식별자 (정수)
- 상자 = b = 해시 테이블의 크기 (테이블 내에 존재하는 상자의 수 / 즉, 인덱스는 0 ~ b-1 까지 존재한다.)
- 해시 함수 = f(k)
게산식 [ f(k) = k % b ]
위의 해시 함수 계산식은 정수로 이루어진 키를 간단하게 해시 테이블의 인덱스에 매핑하는 방법이다.
해당 함수를 통해 키를 고르게 분산시켜 테이블의 공간을 효율적으로 사용하도록 돕는다.
만약 20개의 상자(b = 20)를 가진 해시 테이블인 경우 아래와 같은 매핑을 생성한다.
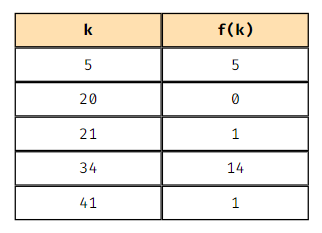
키 = 5는 해시 테이블의 5번 인덱스에 저장되고
키 = 20은 해시 테이블의 0번 인덱스에 저장되는 형식이 된다.
다만 여기서 k가 21과 41은 동일한 인덱스인 1에 저장하게 된다.
(둘 이상의 서로 다른 값을 같은 상자로 매핑하게 된다.)
즉, 서로 다른 키가 동일한 인덱스로 해시될 수 있는데
이를 해시 충돌(Hash Collision)이라고 한다.
해시 함수에 입력은 숫자로 제한되지 않는다.
위 방법은 키가 정수인 경우에 예시를 든 방법으로
정수가 아니라 문자열을 사용하는 방법도 있다.
해시 충돌(Hash Collision)은
해시 테이블에서 데이터를 저장할 때 발생할 수 있는 일반적인 문제로
해당 충돌 문제를 해결하지 않으면 새로운 데이터가 기존 데이터를 덮어쓰게 되어 데이터가 손실된다.
세상에서 가장 좋은 해시 함수도 키와 상자(해시 값)를 완벽하게 1:1로 매핑하지는 못한다.
완벽한 1:1 매핑을 위해서는 엄청 큰 배열을 사용해야 하며,
이에 따라 메모리 사용도 엄청 늘어나기 때문이다.
그리고 큰 집합(키)을 더 작은 집합(해시 값)으로 매핑하는 수학 함수의 경우 가끔 충돌이 발생할 수밖에 없다.
이러한 경우에는
해시 테이블의 크기를 늘리거나 더 나은 해시 함수를 선택함으로써 충돌을 완화할 수는 있지만
결국 키 공간이 상자 개수보다 크다면, 충돌을 완전히 제거하는 것은 불가능하다.
따라서 같은 위치(상자)를 차지하려는 둘 이상의 데이터를 좋게 처리하는 방법이 필요하다.
여러 방법들이 존재하지만 그중에서 일반적인 2가지 방법
- 체이닝(chaining) = 충돌 발생 시 해당 상자(인덱스)에 연결 리스트로 저장
- 선형 탐색(linear probing) = 충돌 발생시 다른(다음) 빈 상자를 찾아 저장
--
체이닝 (chaining)
--
체이닝은
각 상자 안에 추가 구조를 사용해서 해시 테이블의 충돌을 처리하는 방법이다.
각 상자에 고정된 데이터(또는 단일 데이터에 대한 포인터)를 저장하는 대신
연결 리스트의 머리를 가리키는 포인터를 저장한다.
즉, 해시 테이블의 각 인덱스를 연결 리스트 또는 다른 동적 자료 구조로 사용하여
여러 데이터를 저장하는 방법이다.
ListNode 클래스
public class ListNode {
// 키와 값은 타입을 제네릭으로 지정할 수 있습니다.
private Object key;
private Object value;
ListNode next; // 다음 ListNode
}
해시 테이블 클래스
public class HashTable {
private int size;
private LinkedList<ListNode>[] bins;
// 생성자 - 해시 테이블의 크기를 받아서 초기화합니다.
public HashTable(int size) {
this.size = size;
bins = new LinkedList[size];
// 각 인덱스에 대해 LinkedList 초기화
for (int i = 0; i < size; i++) {
bins[i] = new LinkedList<>();
}
}
}
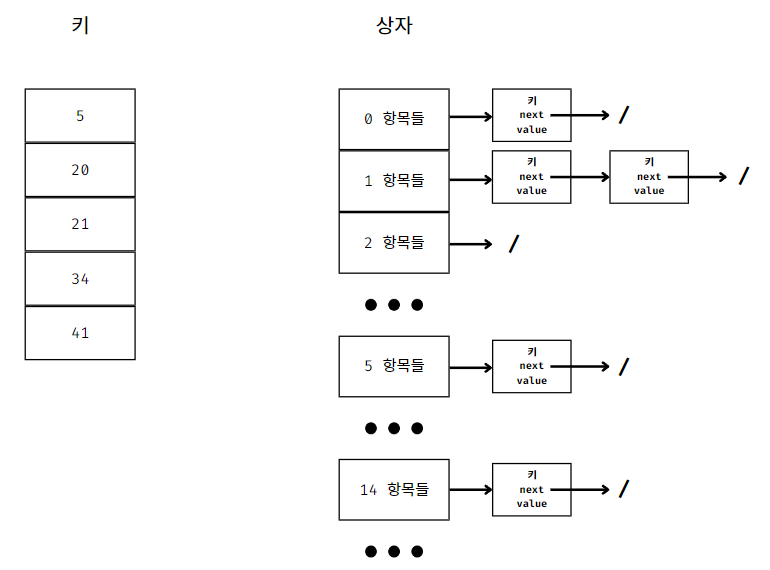
위 그림처럼
충돌이 일어난(1 항목) 상자 안에 여러 항목을 저장하기 위해 연결 리스트를 사용한 해시 테이블 구조이다.
체이닝을 통해 해시 테이블에 새 항목을 삽입하는 예시 코드 [JAVA]
public class HashTable {
private int size;
private ListNode[] bins;
// 생성자 - 해시 테이블의 크기를 받아서 초기화합니다.
public HashTable(int size) {
this.size = size;
bins = new ListNode[size];
}
// 해시 함수 - 간단하게 키를 해시 테이블의 크기로 나눈 나머지를 반환합니다.
private int hashFunction(Object key) {
return key.hashCode() % size;
}
// 해시 테이블에 데이터를 삽입하는 메서드
public void hashTableInsert(Object key, Object value) {
// 먼저 키의 해시 값을 계산
int hashValue = hashFunction(key);
// 계산한 해당 해시 값의 상자가 비어있다면 새로운 ListNode를 생성하여 삽입
if (bins[hashValue] == null) {
bins[hashValue] = new ListNode(key, value);
return;
}
// 계산한 해당 해시 값의 상자가 비어있지 않다면
ListNode current = bins[hashValue];
// 연결 리스트를 스캔하며 동일한 키가 존재하는 지 확인
while (!current.getKey().equals(key) && current.next != null) {
current = current.next;
}
// 동일한 키가 존재하는 경우 값을 업데이트
if (current.getKey().equals(key)) {
current.setValue(value);
} else {
// 키가 존재하지 않으면 새로운 노드를 연결 리스트에 추가
current.next = new ListNode(key, value);
}
}
// ListNode 클래스
private class ListNode {
private Object key;
private Object value;
ListNode next;
public ListNode(Object key, Object value) {
this.key = key;
this.value = value;
this.next = null;
}
...
}
}
탐색하는 예시 코드 [JAVA]
public class HashTable {
private int size;
private ListNode[] bins;
// 생성자 - 해시 테이블의 크기를 받아서 초기화합니다.
public HashTable(int size) {
this.size = size;
bins = new ListNode[size];
}
// 해시 함수 - 간단하게 키를 해시 테이블의 크기로 나눈 나머지를 반환합니다.
private int hashFunction(Object key) {
return key.hashCode() % size;
}
// 해시 테이블에서 데이터를 검색하는 메서드
public Object hashTableLookup(Object key) {
// 먼저 키의 해시 값을 계산
int hashValue = hashFunction(key);
// 해당 인덱스(상자)가 비어있으면 null을 반환
if (bins[hashValue] == null) {
return null;
}
// 해당 인덱스에서 연결 리스트를 순회하며 키를 찾음
ListNode current = bins[hashValue];
while (!current.getKey().equals(key) && current.next != null) {
current = current.next;
}
// 키가 존재하면 값을 반환
if (current.getKey().equals(key)) {
return current.getValue();
}
// 키를 찾지 못하면 null을 반환
return null;
}
// ListNode 클래스
private class ListNode {
private Object key;
private Object value;
ListNode next;
public ListNode(Object key, Object value) {
this.key = key;
this.value = value;
this.next = null;
}
...
}
}
항목을 제거하는 예시 코드 [JAVA]
public class HashTable {
private int size;
private ListNode[] bins;
// 생성자 - 해시 테이블의 크기를 받아서 초기화합니다.
public HashTable(int size) {
this.size = size;
bins = new ListNode[size];
}
// 해시 함수 - 간단하게 키를 해시 테이블의 크기로 나눈 나머지를 반환합니다.
private int hashFunction(Object key) {
return key.hashCode() % size;
}
// 해시 테이블에서 데이터를 삭제하는 메서드
public ListNode hashTableRemove(Object key) {
// 먼저 키의 해시 값을 계산
int hashValue = hashFunction(key);
// 해당 인덱스가 비어있으면 null을 반환
if (bins[hashValue] == null) {
return null;
}
ListNode current = bins[hashValue]; // 현재 노드
ListNode last = null; // 이전 노드
// 연결 리스트를 순회하며 키를 찾음
while (!current.getKey().equals(key) && current.next != null) {
last = current; // 현재 노드
current = current.next; // 다음 노드
}
// 키가 존재하면 해당 노드를 제거
if (current.getKey().equals(key)) {
if (last != null) {
// 중간이나 끝에 있는 노드를 제거 (이전 노드에서 다음 노드를 현재 노드의 다음 노드를 가리키도록 수정)
last.next = current.next;
} else {
// 첫 번째 노드를 제거
bins[hashValue] = current.next;
}
return current;
}
// 키를 찾지 못하면 null을 반환
return null;
}
// ListNode 클래스
private class ListNode {
private Object key;
private Object value;
ListNode next;
public ListNode(Object key, Object value) {
this.key = key;
this.value = value;
this.next = null;
}
...
}
}--
해시 함수 (Hash Function)
--
해시 함수는
데이터를 고정된 크기의 숫자 값으로 변환하는 함수다.
여기서 변환한 숫자를
- 해시값 (Hash Value)
- 해시 코드 (Hash Code)
- 해시 (Hash)
위의 셋 중에 하나로 불리며
주로 해시 테이블과 같은 데이터 구조에서 데이터를 저장하고 검색하는 데 사용된다.
좋은 해시 함수와 나쁜 해시 함수의 차이는
해시 테이블과 연결 리스트의 차이와 비슷하다.
좋은 해시 함수는 키를 균일하게 상자 전체에 매핑하는 것이며 (충돌 X)
나쁜 해시 함수는 소수의 상자에 키가 몰리는 것이다. (충돌 O)
해시 함수의 핵심 조건
- 결정적
해시 함수는 매번 같은 키를 같은 해시 상자에 매핑해야 한다. - 정해진 크기의 치역을 가짐
해시 함수는 모든 키를 제한된 범위로 매핑해야 하며,
해당 범위는 해시 테이블에 있는 상자의 개수에 해당해야 한다.
숫자가 아닌 키를 사용
숫자 키를 사용하는 경우에는
위에서 사용한 해시 함수처럼 나눗셈 방식과 같은 수학 함수의 치역을 사용할 수 있다.
다만 숫자가 아닌 키를 다뤄야 하는 경우도 존재하기 때문에
문자열의 해시를 계산할 수 있어야 한다.
일반적으로는 숫자가 아닌 입력을 숫자로 변환하는 함수를 사용하는 것이다.
- 각 문자를 아스키(ASCII) 값에 매핑
- 해당 숫자의 합을 계산
- 합계를 나머지 연산을 통해 상자 번호로 매핑
위 방법은
직관적이고 구현하기 쉽지만,
문자가 나타나는 방식으로 인해 해시 값의 분포가 좋지 않을 수 있다.
(해시 함수가 문자 순서를 고려하지 않으므로 "act"와 "cat"은 같은 상자에 매핑된다.)
이렇게 문자열을 해싱하는 방식에서 더 나은 방식 중에 "호너(Horner)의 방법"이라는 접근 방법이 존재한다.
호너(Horner)의 방법은
각 문자의 값을 직접 더하는 대신
첫 번째 문자로부터 이 방식을 통해 계산한 누적 합계에 어떤 상수를 곱한 후 다음 문자의 값을 더하는 방법이다.
public class StringHash {
private static final int CONST = 31; // 예: 31은 보통 좋은 결과를 주는 상수
public static int stringHash(String key, int size) {
int total = 0;
// 각 문자에 대해 해시 값을 계산
for (int i = 0; i < key.length(); i++) {
char character = key.charAt(i);
total = CONST * total + characterToNumber(character);
}
// 해시 값을 테이블 크기로 나눈 나머지를 반환
return total % size;
}
// 문자를 숫자로 변환하는 메서드
private static int characterToNumber(char character) {
return (int) character; // 기본적으로 문자에 해당하는 유니코드 값을 반환
}
}
위 코드에서 CONST는
곱셈에 사용할 상수로, 일반적으로 문자들의 값 중 가장 큰 값보다 더 큰 소수를 사용한다.
--
해시 테이블이란 무엇일까?
키를 사용한 저장 및 탐색
--
정수 값을 효율적으로 탐색하기 위한 이상적인 인덱싱 방법을 생각해 보면
모든 값에 대해 개별적으로 배열 상자를 유지하고,
값을 사용하여 해당 상자를 인덱싱하는 것이다.
인덱싱(Indexing)은
데이터를 효율적으로 검색하고 조회하기 위해
데이터의 위치나 상태를 체계적으로 정리하는 과정을 의미한다.
예시) 도서관에서 책을 쉽게 찾기 위해 책의 위치를 정리하는 것
간단한 예시를 들면
값 9를 삽입하기 위해 인덱스가 9인 상자에 넣는다.
다만 이러한 자료 구조에는 존재할 수 있는 모든 키의 배열을 유지하기 위해 엄청난 비용이 들게 된다.
예시로 16자리 신용카드 번호를 모두 저장하려면 10^16개의 상자가 필요하게 된다. (아주 큰 메모리가 필요)
여기서 더 큰 문제는 해당 모든 상자를 사용할 가능성이 매우 낮아 메모리 낭비가 된다.
그리고 키 값이 정수가 아니면 사용할 수가 없다.
컴퓨터 프로그램은 종종 키(key)를 사용하여 레코드를 식별한다.
키(key)는
데이터와 함께 저장되거나
데이터로부터 유도된 단일 값이며,
레코드를 식별할 때 키를 사용할 수 있다.
즉, 데이터베이스에서 특정 데이터를 고유하게 식별할 수 있는 값을 의미한다.
데이터베이스의 테이블 내의 특정 컬럼에서 유일한 값을 가지고 있으며
이를 통해 데이터의 중복을 피하고 데이터 검색 속도를 높인다.
레코드(Record)는
데이터베이스(테이블)에서 하나의 행(row) 또는 엔트리(entry)를 의미한다.
레코드는 튜플(Tuple)이라고도 부른다.
--
해시 테이블(Hash Table)
--
해시 테이블은
수학 함수를 사용해서 데이터의 위치를 알려주는 자료 구조로
특히 정보를 탐색해서 빠르게 읽고 싶은 순수한 저장 용도의 경우에 해시 테이블이 유용하다.
수학적인 매핑을 사용해 키 공간을 압축한다.
키(key)를 테이블상 위치(해시 값)로 매핑하는 해시 함수를 사용해서 큰 키 공간을 작은 영역으로 축소시킨다.
즉, 키(key)와 값(value)을 매핑하여 데이터를 효율적으로 저장하고 검색할 수 있는 구조다.
이 매핑을 통해서 키를 배열로 사용했을 경우의 두 가지 문제를 해결할 수 있다.
- 키를 저장하는 아주 많은 상자가 필요하지 않다 (값의 개수와 키의 개수가 동일)
- 키에 정수가 아닌 값도 사용이 가능
정수로 이루어진 키(key)에 대해 간단한 해시 함수를 정의하는 방법
- 키 = k = 해시 테이블에 저장하려는 데이터의 고유한 식별자 (정수)
- 상자 = b = 해시 테이블의 크기 (테이블 내에 존재하는 상자의 수 / 즉, 인덱스는 0 ~ b-1 까지 존재한다.)
- 해시 함수 = f(k)
게산식 [ f(k) = k % b ]
위의 해시 함수 계산식은 정수로 이루어진 키를 간단하게 해시 테이블의 인덱스에 매핑하는 방법이다.
해당 함수를 통해 키를 고르게 분산시켜 테이블의 공간을 효율적으로 사용하도록 돕는다.
만약 20개의 상자(b = 20)를 가진 해시 테이블인 경우 아래와 같은 매핑을 생성한다.
키 = 5는 해시 테이블의 5번 인덱스에 저장되고
키 = 20은 해시 테이블의 0번 인덱스에 저장되는 형식이 된다.
다만 여기서 k가 21과 41은 동일한 인덱스인 1에 저장하게 된다.
(둘 이상의 서로 다른 값을 같은 상자로 매핑하게 된다.)
즉, 서로 다른 키가 동일한 인덱스로 해시될 수 있는데
이를 해시 충돌(Hash Collision)이라고 한다.
해시 함수에 입력은 숫자로 제한되지 않는다.
위 방법은 키가 정수인 경우에 예시를 든 방법으로
정수가 아니라 문자열을 사용하는 방법도 있다.
해시 충돌(Hash Collision)은
해시 테이블에서 데이터를 저장할 때 발생할 수 있는 일반적인 문제로
해당 충돌 문제를 해결하지 않으면 새로운 데이터가 기존 데이터를 덮어쓰게 되어 데이터가 손실된다.
세상에서 가장 좋은 해시 함수도 키와 상자(해시 값)를 완벽하게 1:1로 매핑하지는 못한다.
완벽한 1:1 매핑을 위해서는 엄청 큰 배열을 사용해야 하며,
이에 따라 메모리 사용도 엄청 늘어나기 때문이다.
그리고 큰 집합(키)을 더 작은 집합(해시 값)으로 매핑하는 수학 함수의 경우 가끔 충돌이 발생할 수밖에 없다.
이러한 경우에는
해시 테이블의 크기를 늘리거나 더 나은 해시 함수를 선택함으로써 충돌을 완화할 수는 있지만
결국 키 공간이 상자 개수보다 크다면, 충돌을 완전히 제거하는 것은 불가능하다.
따라서 같은 위치(상자)를 차지하려는 둘 이상의 데이터를 좋게 처리하는 방법이 필요하다.
여러 방법들이 존재하지만 그중에서 일반적인 2가지 방법
- 체이닝(chaining) = 충돌 발생 시 해당 상자(인덱스)에 연결 리스트로 저장
- 선형 탐색(linear probing) = 충돌 발생시 다른(다음) 빈 상자를 찾아 저장
--
체이닝 (chaining)
--
체이닝은
각 상자 안에 추가 구조를 사용해서 해시 테이블의 충돌을 처리하는 방법이다.
각 상자에 고정된 데이터(또는 단일 데이터에 대한 포인터)를 저장하는 대신
연결 리스트의 머리를 가리키는 포인터를 저장한다.
즉, 해시 테이블의 각 인덱스를 연결 리스트 또는 다른 동적 자료 구조로 사용하여
여러 데이터를 저장하는 방법이다.
ListNode 클래스
public class ListNode {
// 키와 값은 타입을 제네릭으로 지정할 수 있습니다.
private Object key;
private Object value;
ListNode next; // 다음 ListNode
}
해시 테이블 클래스
public class HashTable {
private int size;
private LinkedList<ListNode>[] bins;
// 생성자 - 해시 테이블의 크기를 받아서 초기화합니다.
public HashTable(int size) {
this.size = size;
bins = new LinkedList[size];
// 각 인덱스에 대해 LinkedList 초기화
for (int i = 0; i < size; i++) {
bins[i] = new LinkedList<>();
}
}
}
위 그림처럼
충돌이 일어난(1 항목) 상자 안에 여러 항목을 저장하기 위해 연결 리스트를 사용한 해시 테이블 구조이다.
체이닝을 통해 해시 테이블에 새 항목을 삽입하는 예시 코드 [JAVA]
public class HashTable {
private int size;
private ListNode[] bins;
// 생성자 - 해시 테이블의 크기를 받아서 초기화합니다.
public HashTable(int size) {
this.size = size;
bins = new ListNode[size];
}
// 해시 함수 - 간단하게 키를 해시 테이블의 크기로 나눈 나머지를 반환합니다.
private int hashFunction(Object key) {
return key.hashCode() % size;
}
// 해시 테이블에 데이터를 삽입하는 메서드
public void hashTableInsert(Object key, Object value) {
// 먼저 키의 해시 값을 계산
int hashValue = hashFunction(key);
// 계산한 해당 해시 값의 상자가 비어있다면 새로운 ListNode를 생성하여 삽입
if (bins[hashValue] == null) {
bins[hashValue] = new ListNode(key, value);
return;
}
// 계산한 해당 해시 값의 상자가 비어있지 않다면
ListNode current = bins[hashValue];
// 연결 리스트를 스캔하며 동일한 키가 존재하는 지 확인
while (!current.getKey().equals(key) && current.next != null) {
current = current.next;
}
// 동일한 키가 존재하는 경우 값을 업데이트
if (current.getKey().equals(key)) {
current.setValue(value);
} else {
// 키가 존재하지 않으면 새로운 노드를 연결 리스트에 추가
current.next = new ListNode(key, value);
}
}
// ListNode 클래스
private class ListNode {
private Object key;
private Object value;
ListNode next;
public ListNode(Object key, Object value) {
this.key = key;
this.value = value;
this.next = null;
}
...
}
}
탐색하는 예시 코드 [JAVA]
public class HashTable {
private int size;
private ListNode[] bins;
// 생성자 - 해시 테이블의 크기를 받아서 초기화합니다.
public HashTable(int size) {
this.size = size;
bins = new ListNode[size];
}
// 해시 함수 - 간단하게 키를 해시 테이블의 크기로 나눈 나머지를 반환합니다.
private int hashFunction(Object key) {
return key.hashCode() % size;
}
// 해시 테이블에서 데이터를 검색하는 메서드
public Object hashTableLookup(Object key) {
// 먼저 키의 해시 값을 계산
int hashValue = hashFunction(key);
// 해당 인덱스(상자)가 비어있으면 null을 반환
if (bins[hashValue] == null) {
return null;
}
// 해당 인덱스에서 연결 리스트를 순회하며 키를 찾음
ListNode current = bins[hashValue];
while (!current.getKey().equals(key) && current.next != null) {
current = current.next;
}
// 키가 존재하면 값을 반환
if (current.getKey().equals(key)) {
return current.getValue();
}
// 키를 찾지 못하면 null을 반환
return null;
}
// ListNode 클래스
private class ListNode {
private Object key;
private Object value;
ListNode next;
public ListNode(Object key, Object value) {
this.key = key;
this.value = value;
this.next = null;
}
...
}
}
항목을 제거하는 예시 코드 [JAVA]
public class HashTable {
private int size;
private ListNode[] bins;
// 생성자 - 해시 테이블의 크기를 받아서 초기화합니다.
public HashTable(int size) {
this.size = size;
bins = new ListNode[size];
}
// 해시 함수 - 간단하게 키를 해시 테이블의 크기로 나눈 나머지를 반환합니다.
private int hashFunction(Object key) {
return key.hashCode() % size;
}
// 해시 테이블에서 데이터를 삭제하는 메서드
public ListNode hashTableRemove(Object key) {
// 먼저 키의 해시 값을 계산
int hashValue = hashFunction(key);
// 해당 인덱스가 비어있으면 null을 반환
if (bins[hashValue] == null) {
return null;
}
ListNode current = bins[hashValue]; // 현재 노드
ListNode last = null; // 이전 노드
// 연결 리스트를 순회하며 키를 찾음
while (!current.getKey().equals(key) && current.next != null) {
last = current; // 현재 노드
current = current.next; // 다음 노드
}
// 키가 존재하면 해당 노드를 제거
if (current.getKey().equals(key)) {
if (last != null) {
// 중간이나 끝에 있는 노드를 제거 (이전 노드에서 다음 노드를 현재 노드의 다음 노드를 가리키도록 수정)
last.next = current.next;
} else {
// 첫 번째 노드를 제거
bins[hashValue] = current.next;
}
return current;
}
// 키를 찾지 못하면 null을 반환
return null;
}
// ListNode 클래스
private class ListNode {
private Object key;
private Object value;
ListNode next;
public ListNode(Object key, Object value) {
this.key = key;
this.value = value;
this.next = null;
}
...
}
}--
해시 함수 (Hash Function)
--
해시 함수는
데이터를 고정된 크기의 숫자 값으로 변환하는 함수다.
여기서 변환한 숫자를
- 해시값 (Hash Value)
- 해시 코드 (Hash Code)
- 해시 (Hash)
위의 셋 중에 하나로 불리며
주로 해시 테이블과 같은 데이터 구조에서 데이터를 저장하고 검색하는 데 사용된다.
좋은 해시 함수와 나쁜 해시 함수의 차이는
해시 테이블과 연결 리스트의 차이와 비슷하다.
좋은 해시 함수는 키를 균일하게 상자 전체에 매핑하는 것이며 (충돌 X)
나쁜 해시 함수는 소수의 상자에 키가 몰리는 것이다. (충돌 O)
해시 함수의 핵심 조건
- 결정적
해시 함수는 매번 같은 키를 같은 해시 상자에 매핑해야 한다. - 정해진 크기의 치역을 가짐
해시 함수는 모든 키를 제한된 범위로 매핑해야 하며,
해당 범위는 해시 테이블에 있는 상자의 개수에 해당해야 한다.
숫자가 아닌 키를 사용
숫자 키를 사용하는 경우에는
위에서 사용한 해시 함수처럼 나눗셈 방식과 같은 수학 함수의 치역을 사용할 수 있다.
다만 숫자가 아닌 키를 다뤄야 하는 경우도 존재하기 때문에
문자열의 해시를 계산할 수 있어야 한다.
일반적으로는 숫자가 아닌 입력을 숫자로 변환하는 함수를 사용하는 것이다.
- 각 문자를 아스키(ASCII) 값에 매핑
- 해당 숫자의 합을 계산
- 합계를 나머지 연산을 통해 상자 번호로 매핑
위 방법은
직관적이고 구현하기 쉽지만,
문자가 나타나는 방식으로 인해 해시 값의 분포가 좋지 않을 수 있다.
(해시 함수가 문자 순서를 고려하지 않으므로 "act"와 "cat"은 같은 상자에 매핑된다.)
이렇게 문자열을 해싱하는 방식에서 더 나은 방식 중에 "호너(Horner)의 방법"이라는 접근 방법이 존재한다.
호너(Horner)의 방법은
각 문자의 값을 직접 더하는 대신
첫 번째 문자로부터 이 방식을 통해 계산한 누적 합계에 어떤 상수를 곱한 후 다음 문자의 값을 더하는 방법이다.
public class StringHash {
private static final int CONST = 31; // 예: 31은 보통 좋은 결과를 주는 상수
public static int stringHash(String key, int size) {
int total = 0;
// 각 문자에 대해 해시 값을 계산
for (int i = 0; i < key.length(); i++) {
char character = key.charAt(i);
total = CONST * total + characterToNumber(character);
}
// 해시 값을 테이블 크기로 나눈 나머지를 반환
return total % size;
}
// 문자를 숫자로 변환하는 메서드
private static int characterToNumber(char character) {
return (int) character; // 기본적으로 문자에 해당하는 유니코드 값을 반환
}
}
위 코드에서 CONST는
곱셈에 사용할 상수로, 일반적으로 문자들의 값 중 가장 큰 값보다 더 큰 소수를 사용한다.
--