
데이터를 메모리에 저장하는 방법?
서론
--
일반적으로 컴퓨터 프로그램이라면 무엇이든 데이터를 메모리에 저장 및 접근이 가능해야 한다.
이러한 각 데이터들은 프로그램이 의도하는 기능을 수행하는 데 꼭 필요하다.
데이터를 메모리에 저장하는 기본적인 방법을 알아보자.
- 변수
- 복합 자료 구조
- 배열
--
변수
--
변수는
컴퓨터 메모리 내부에 데이터의 위치 또는 주소를 표현하는 이름이다.
변수를 사용하게 되면
데이터를 사용할 때 사용한 변수 이름을 이용하여 저장된 데이터를 읽을 수 있으며
변수 이름만 알고 있다면 데이터의 메모리 위치를 알 필요가 없어진다.
변수가 없다면 프로그램의 내부 상태를 추적, 평가, 변경할 수 없다.
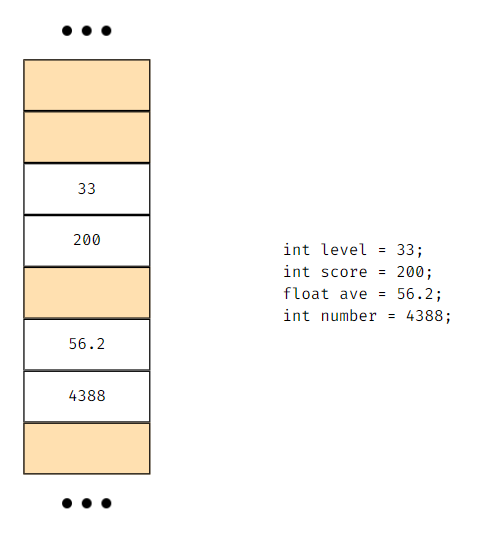
위 그림처럼 변수를 저장하게 되면
해당 데이터가 메모리 내부에 저장하게 되는데
이때 메모리 내부 어디에 저장되어 있는지 알 필요 없이 변수명을 사용하면 알아서 해당 데이터를 가져다가 사용할 수 있다.
위 그림처럼 컴퓨터의 메모리는 여러 상자가 일렬로 늘어선 것처럼 생각하면 편하다.
각 변수는 저장한 데이터의 크기에 따라 하나 이상의 인접한 상자를 차지하게 된다.
예시로 각 상자는 1byte의 크기를 할당할 수 있다고 가정하자.
int 타입은 4byte의 크기로 int형 변수는 총 4개의 상자를 차지하게 된다.
(메모리에서 연속된 1byte 4개의 공간을 차지)
--
복합 자료 구조
--
복합 자료 구조는
관련 있는 변수들을 모아놓은 구조를 의미한다.
예시로 여러 변수들을 한 그룹으로 엮은 구조제(struct) 또는 객체(object)가 복합 자료 구조에 속한다.
커피에 대한 정보를 묶은 객체 예시 코드 [JAVA]
public class Coffee {
private String name;
private String size;
private String milk;
private int sugar;
private double price;
}
위 코드처럼 커피에 대한 정보를 하나의 복합 자료 구조(객체)에 저장하면
커피에 대한 정보가 담긴 변수들을 따로 추적하여 관리하지 않아도 된다.
복합 자료 구조(객체)를 사용하는 코드에서 변수에 접근하려면
"객체이름.필드이름"으로 변수에 접근할 수 있다.
Coffee americano = new Coffee();
americano.name = americacano;
--
배열
--
배열은
관련된 다수의 값을 저장할 때 사용한다.
이때 메모리에서 연속적으로 인덱스(index)가 부여된 상자에 데이터를 저장하게 된다.
인덱스(index)란
배열 요소에 접근하기 위해 사용되는 위치 표시자로
배열은 관련된 데이터들이 연속적인 상자에 저장되는데
배열 내부에 연속적으로 존재하는 데이터 중에 특정 데이터를 식별하고 조작할 수 있도록 도와준다.
즉, 인덱스는 배열 내부에 존재하는 일련 된 상자(공간)의 순서를 의미하며
인덱스(순서)를 통해 배열 내부에 특정 요소를 식별하고 조작할 수 있게 된다.
인덱스는 0부터 시작한다.
0부터 사용하는 이유는
메모리 내에서 배열의 시작점부터 오프셋을 사용해 위치를 계산할 때 편리하기 때문이다.
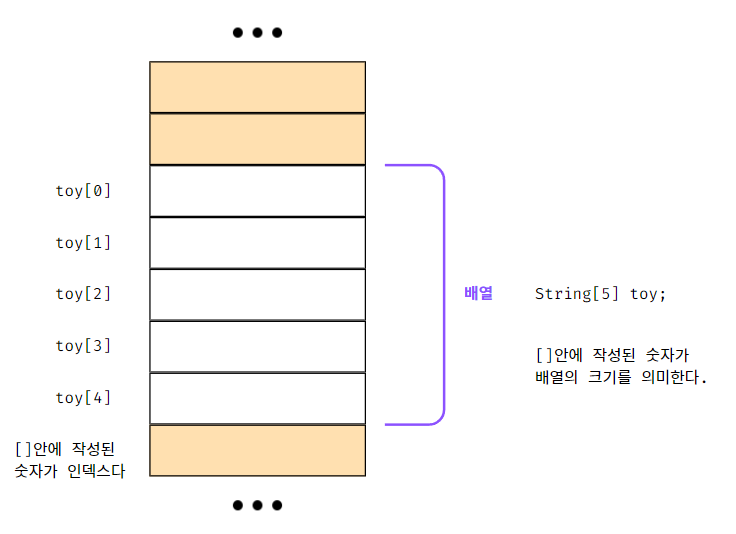
위 그림처럼 배열은 연속된 메모리 상자에 저장하게 되며
배열의 구조는 위치 또는 인덱스를 사용하여 배열 내부의 개별 공간(원소)에 접근할 수 있다.
배열 내부의 상자들은 컴퓨터 메모리에서 서로 인접해 있으므로
첫 번째 원소로부터 오프셋(offset)을 계산하여 해당하는 위치의 메모리를 읽는 방식으로 각 상자에 쉽게 접근할 수 있다.
오프셋(offset)이란
배열이나 메모리와 같이 연속된 데이터 구조 내에서 특정 요소나 위치를 참조하는 데 사용하는
상대적인 위치를 의미한다.
즉, 오프셋으로 특정 위치를 지정하고 해당 오프셋을 이용하여 다른 위치에 존재하는 데이터들은 오프셋과의 거리 계산을 통해 접근하는 것이다.
보통 오프셋은 시작 지점이나 기준 지점에서부터의 거리를 나타낸다.
배열에서 사용하는 오프셋 의미
배열의 시작 지점으로부터 특정 요소까지의 상대적인 위치를 의미로
배열의 첫 번째 요소는 오프셋 0을 가지며
두 번째 요소는 오프셋 1을 가지는 식으로 사용한다.
메모리에서 사용하는 오프셋 의미
기준 주소(base address)로부터 특정 메모리 위치까지의 거리를 나타내는 데 사용한다.
주로 메모리 주소를 계산하는 데 사용한다.
삽입 정렬
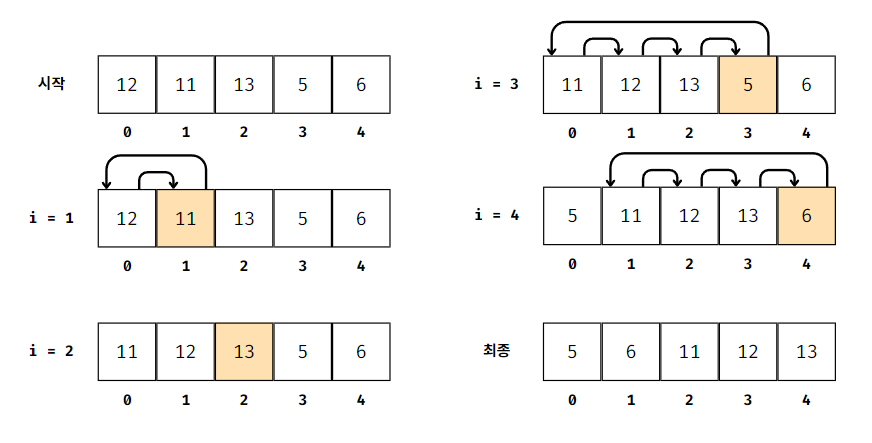
삽입 정렬은
배열의 값을 정렬하는 알고리즘으로, 순서를 정할 수 있는 모든 유형의 값에서 작동한다.
배열의 일부를 정렬하고, 이 정렬된 범위를 전체 배열이 정렬될 때까지 확장하게 된다.
정렬되지 않은 배열의 각 원소를 반복하면서 정렬된 부분의 올반른 위치로 이동시킨다.
삽입 정렬 예시 코드 [JAVA]
public class SortTest {
public static void sortTest(int[] array) {
int n = array.length;
// 배열의 인덱스 1부터 끝까지 반복
for(int i = 1; i < n; ++i) {
int key = array[i]; // 현재 인덱스의 값을 따로 보관
int j = i - 1; // 현재 인덱스-1 (현재 인덱스 값과 비교할 인덱스 최대 범위 지정)
// j 인덱스가 0까지(끝까지) 가거나 j 인덱스의 값이 현재 값보다 클 때까지 반복
while(j >= 0 && array[j] > key) {
array[j + 1] = array[j]; // 비교한 j 인덱스 값을 한 칸 위로 옮김
j = j - 1;
}
array[j + 1] = key; // 현재 값을 최종 위치에 삽입
}
}
public static void main(String[] args) {
int[] array = {12, 11, 13, 5, 6};
sortTest(array);
}
}
--
문자열
--
문자열은 사실 특수한 종류의 배열로
문자로 이루어진 배열이다.
문자열의 각 칸에는 "문자", "숫자", "기호", "공백"으로 구성할 수 있으며
해당 배열의 마지막에는 특수 기호 "/"로 문자열의 끝을 나타낸다.
이 또한 문자로 이루어진 배열이기 때문에 인덱스를 사용하여 문자열의 특정 문자에 직접 접근도 가능하다.

두 숫자를 비교할 때에는 "==" 연산으로 한 번에 직접 비교할 수 있지만
두 문자열을 비교할 때에는 각 문자를 반복하여 비교해야 한다.
이 때 서로 일치하지 않는 문자를 발견할 때까지 비교를 하게 된다.
즉, "Hello" == "HellO"로 비교하면 숫자를 비교하는 것처럼 바로 결과가 나타나서 한 번에 비교하는 것처럼 보일 수 있지만
내부적으로 서로 같은 위치(인덱스)에 존재하는 문자를 반복적으로 비교하는 과정을 거치고 결과가 나오는 것이다.
(문자를 비교하기 전에 먼저 두 문자 배열의 크기가 일치한 지부터 비교한다.)
1. "Hello"와 "HellO"의 문자 배열의 크기가 일치한지 검사
2. 인덱스 0의 문자 비교
3. 인덱스 1의 문자 비교
4. 인덱스 2의 문자 비교
...
이렇게 비교하는 과정에서 다른 것이 나오면 해당 문자열은 다르다고 판단하고
(비교 중에 불일치가 나오면 그 뒤에 비교는 하지않고 바로 문자열이 다르다고 판단하고 끝이 난다.)
모두 일치하다고 나오면 해당 문자열은 같다고 판단하게 된다.
--
'CS > 자료구조' 카테고리의 다른 글
| 이진 탐색 트리 (0) | 2024.08.05 |
|---|---|
| 스택과 큐 (+ 깊이 우선 탐색, 너비 우선 탐색) (0) | 2024.08.03 |
| 동적 자료 구조 (+ 연결 리스트) (0) | 2024.08.02 |
| 이진 탐색 (+ 선형 스캔) (0) | 2024.08.01 |
| 자료구조란? (0) | 2024.07.30 |